记录一次docker占用过大导致磁盘爆炸的问题
背景
通过告警发现磁盘被占满
解决方式
通过命令行工具 ncdu 发现这个文件过大 /var/lib/docker/containers/92ca12ee784ccd5dc44c367046d72f6c0cae4668e50fae613567dc0f4de024a3/92ca12ee784ccd5dc44c367046d72f6c0cae4668e50fae613567dc0f4de024a3-json.log‘
1 | ls -lh /var/lib/docker/containers/92ca12ee784ccd5dc44c367046d72f6c0cae4668e50fae613567dc0f4de024a3/92ca12ee784ccd5dc44c367046d72f6c0cae4668e50fae613567dc0f4de024a3-json.log |
检查后发现是一个日志文件,占据了 15G 之多.
使用命令 cat /dev/null > /var/lib/docker/containers/92ca12ee784ccd5dc44c367046d72f6c0cae4668e50fae613567dc0f4de024a3/92ca12ee784ccd5dc44c367046d72f6c0cae4668e50fae613567dc0f4de024a3-json.log 将其清理,因为这个文件如果被一直占用的话直接使用rm是不会释放磁盘空间的。因此直接使用 /dev/null 覆盖文件即可实现立即释放空间的作用
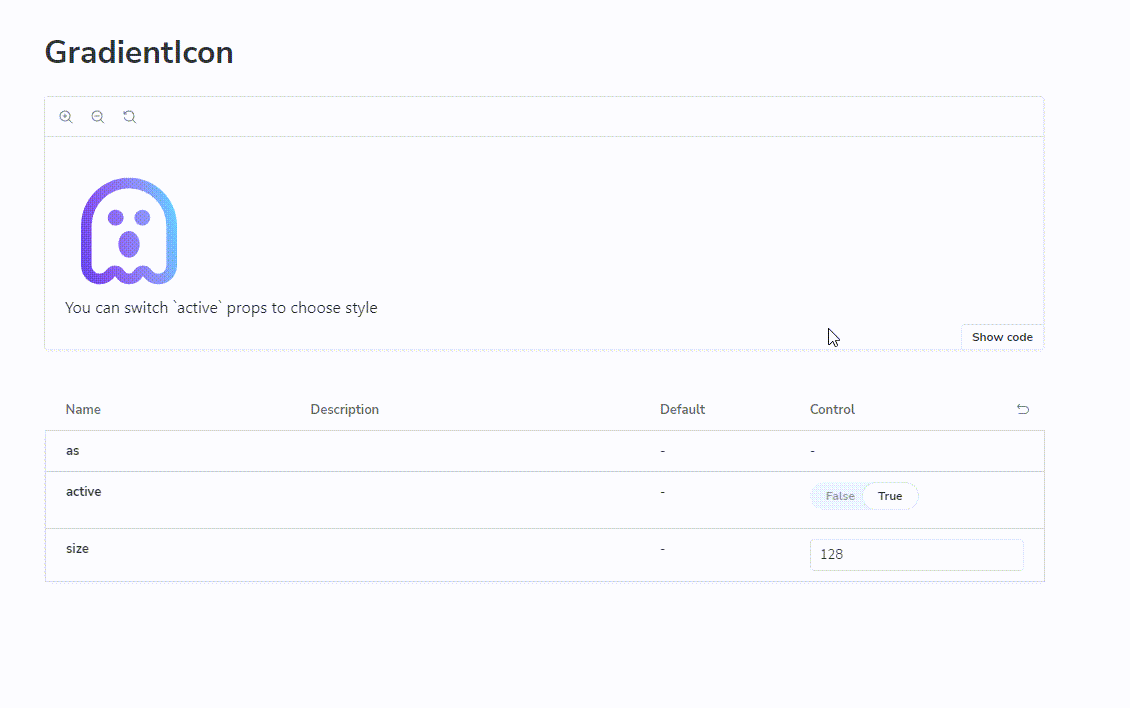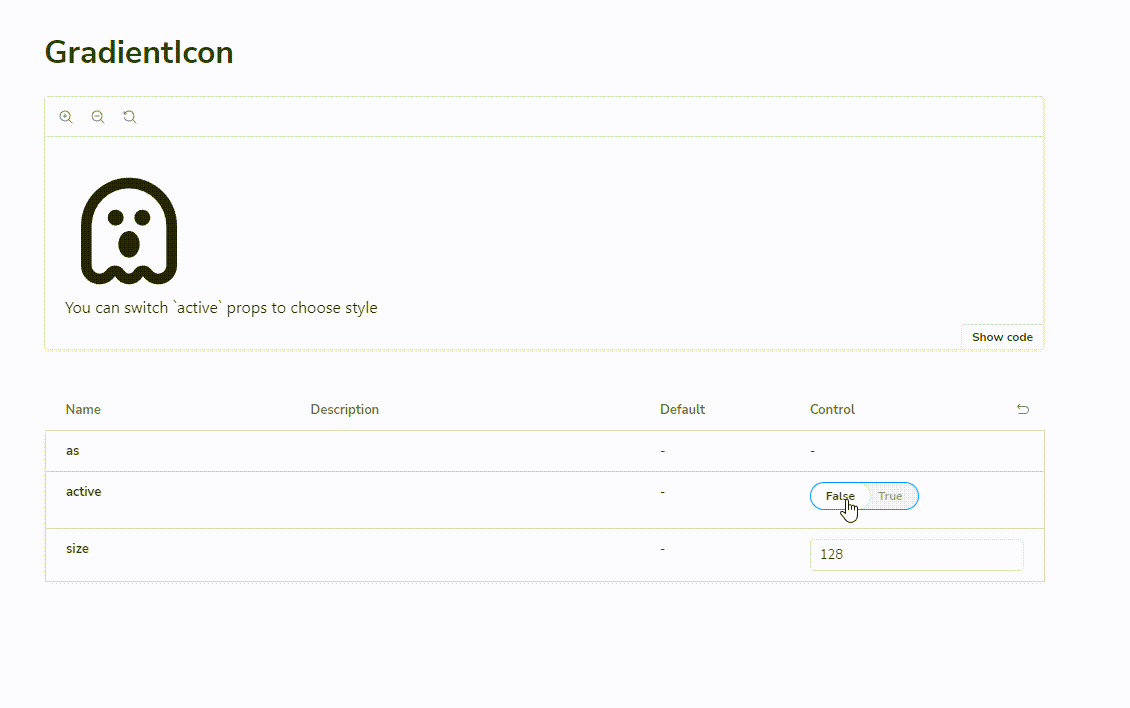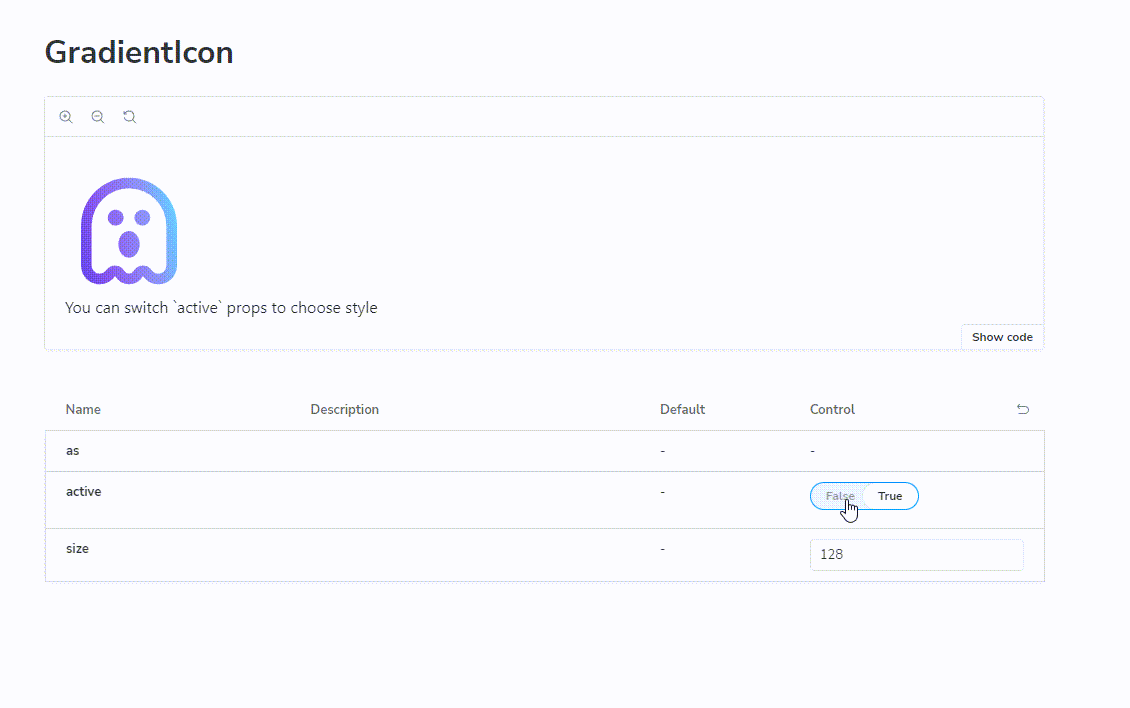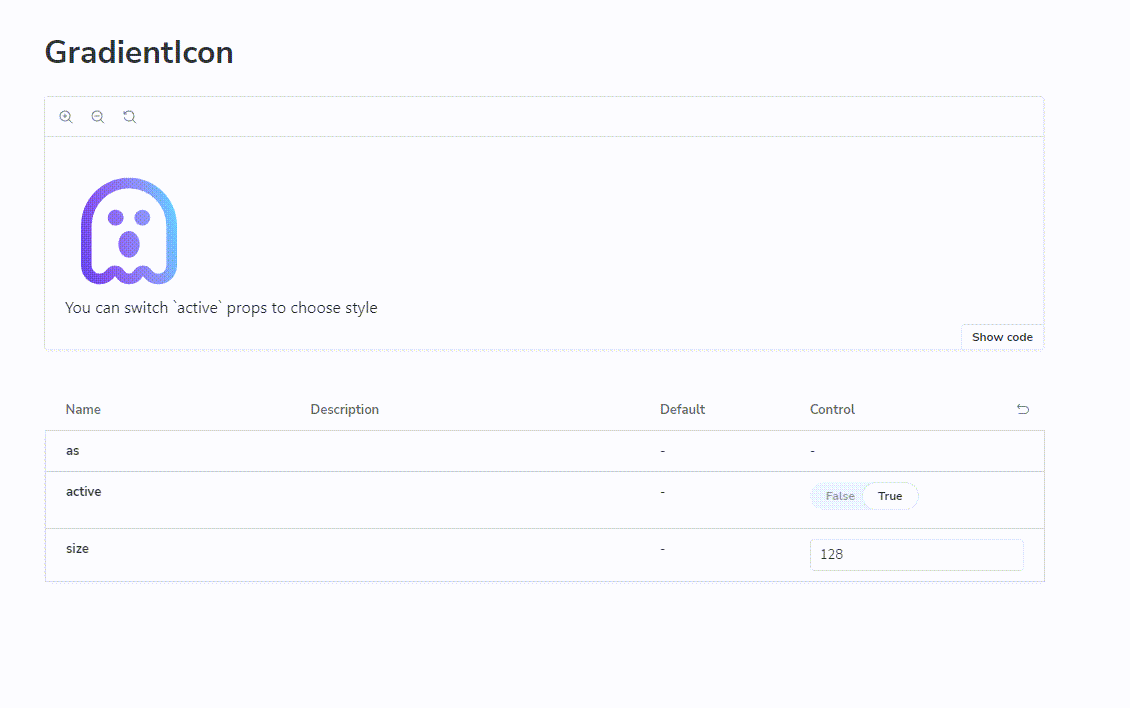
打工人必备!实现JS控制的SVG渐变图标,让你的页面更加生动有趣
在我们开发界面时,有时候渐变的图像会相比固定颜色的图形更加富有层次感与有趣。熟悉css的同学都知道,我们可以通过样式让背景呈现一个线性的渐变图片,比如这样:
1 | .simple-linear { |

也可以通过裁剪背景颜色到文本的方式实现文本颜色渐变
1 | .text-gradient { |

这些解决方案都是网络上随便都能搜到的,那么现在背景渐变有了,文本渐变有了,看上去我们似乎可以实现各种渐变了,但是我们还差一个非常常见的元素没有办法做到渐变,那就是svg图标。
目前网络上所能找到的所有关于svg渐变颜色的方案都是需要通过svg本身的配置来实现的。举个例子:
比如这样:
1 | <svg |

这看上去很美好,因为我们我们只需要把这段svg代码复制到我们的项目中,然后需要的时候引用一下就好了。
当然是可以,但是在实际开发中我们往往会遇到更加复杂的挑战。比如我们用的图标是在一个图标库组件中,我们没有办法去直接修改(比如 react-icons )。比如我们需要让图标在渐变色(选中状态)和单色(未选中状态)之间来回切换。
难道我要准备两个一样的仅仅颜色不一样的图标因为状态来选择使用哪个图标么?这很丑陋,且难以维护。
想象一下我们是如何使用单色图标的?仅仅配置 color=#<hex-color> 即可实现不同颜色的切换。为什么渐变色图标不能有类似方式?
我搜索了网络上所有的资料,但是我没有找到我想要的方法,因此我决定自己探索。
一个很少有人会注意到的事实是,<defs> 标签的定义作用域不是父级的svg节点而是整个文档流。因此我们可以跨多个svg声明共用一个svg定义。然后只需要通过固定的id就可以了。
具体方案如下:
1 | <style> |
只需要我们把第一个表示颜色定义的svg放在全局预先加载,然后给定义的渐变色起一个有意义的名字,然后我们就可以在任意地方直接在svg的样式上告知需要采用的fill颜色即可 fill: url(#my-gradient);
颜色的切换就变成了 fill 属性的切换,这样就和单色图标一样了。
需要注意的是需要给用于声明的svg的宽高设为0,不然浏览器会给一个默认的宽高,会影响整体的布局。
最终看下成品效果:
你可能不需要微前端,但你一定会需要微内核
先聊聊微前端
阿里巴巴的一篇 为iframe正名,你可能并不需要微前端 又将社区的风向一转,当初大力推销微前端概念的阿里巴巴又主动跳出来说微前端未必好用。
虽然不知道阿里巴巴内部发生了什么,但是同样作为一名在工作中深度使用微前端框架的前端码农来说,我想我也逐步触及了微前端的限制。
微前端,简单来说就是把原来iframe实现的隔离机制用js实现了一遍。其背景是为了解决多个团队同时修改一套系统可能带来的项目管理问题,
而微前端的好处在于,iframe的隔离是完全隔离,而微前端是一个可控的隔离。即在某些情况下可以分享一些内容。
微前端的架构往往是由一个基座项目为中心,加上若干个子项目组成。而子项目与子项目之间有一些内容是可以共享的,比如说组件库,公共依赖,缓存管理,权限管理等。这是微前端给我们带来的好处与优势。而曾经的iframe方案则很难做到这一点。
至于iframe方案和微前端的方案的优劣在此不再赘述,但是我想带大家了解一下更容易被我们忽略的东西
什么是微内核
在了解了什么是微前端后,我想向大家介绍一下微内核的概念。
什么是微内核?即以一个核心服务为中心,然后将所有的业务当做一个可插拔的插件。
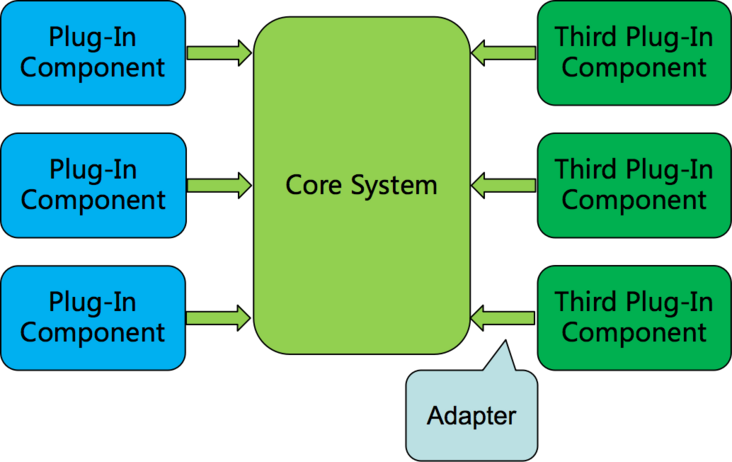
这种架构是不是非常眼熟?没错我们经常用的 vscode 也是这样的微内核框架,vscode 的核心就是一个文本编辑器,然后配套上一个拓展中心用于加载插件。
而像是主题、语言支持、格式化工具以及各种第三方工具面板,都是一个个独立的外部插件。正是因为完整的插件生态造成了 vscode 的成功。而 vscode 的插件系统就是一种微内核架构。
而回过头想想,微前端又何尝不是一种特殊的微内核解决方案呢?微前端无非是基于路由的、限定同时只能加载一个子应用(插件),具备沙盒机制的微内核框架。
微内核架构可以给我们带来什么
在谈论微内核架构时,我们得先抛开一切上下文。聊聊微内核架构的设计理念。
将系统的实现,与系统的基本操作规则区分开来。它实现的方式是将核心功能模块化,划分成几个独立的进程,各自运行,这些进程被称为服务。所有的服务进程,都运行在不同的地址空间。
让服务各自独立,可以减少系统之间的耦合度,易于实现与除错,也可以增进可移植性。它可以避免单一组件失效,而造成整个系统崩溃,内核只需要重启这个组件,不至于影响其他服务器的功能,使系统稳定度增加。同时业务功能可以视需要,抽换或新增某些服务进程,使功能更有弹性。
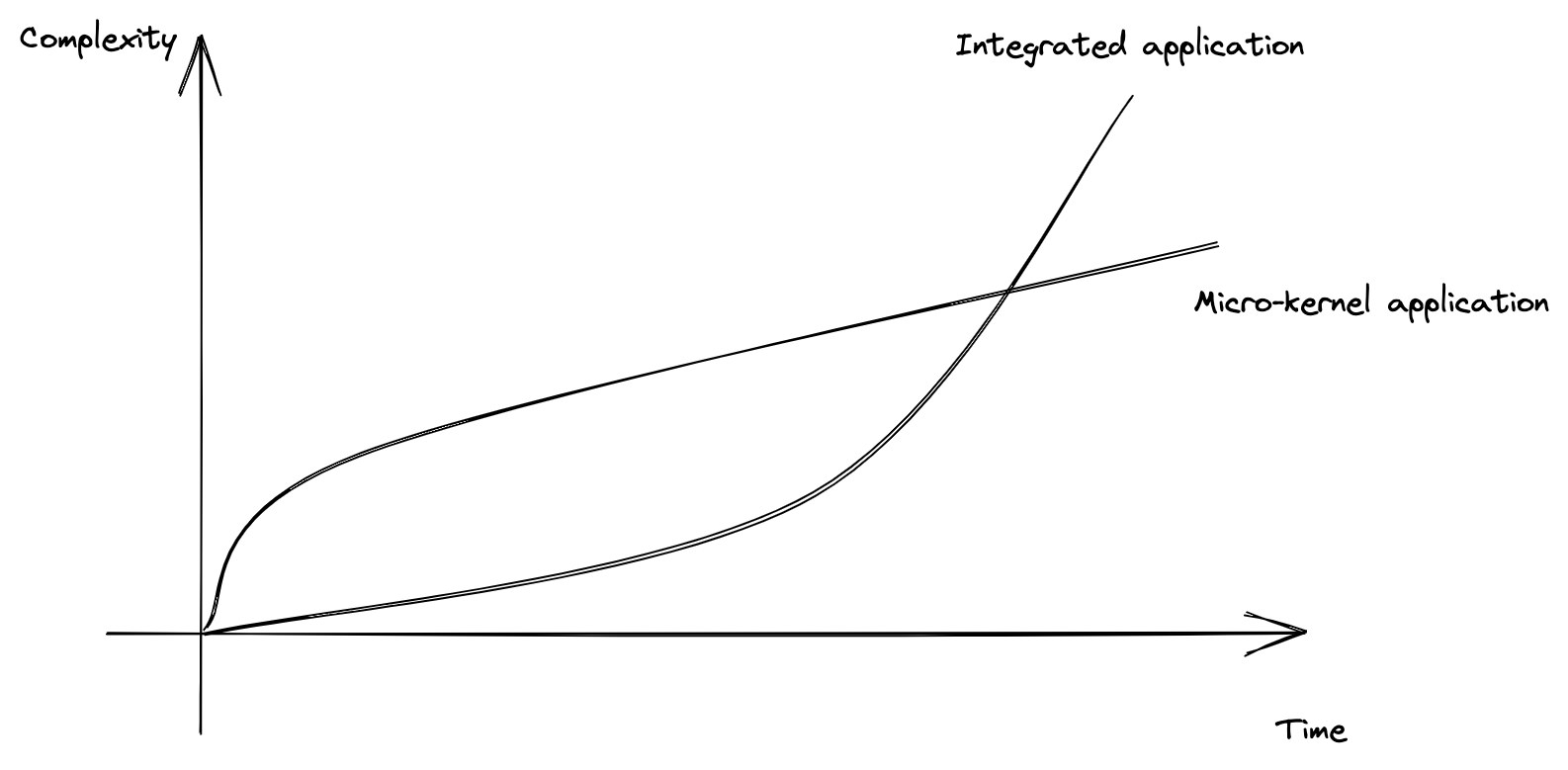
就代码数量来看,一般来说,因为功能简化,核心系统使用的代码比集成式系统更少。更少的代码意味更少的潜藏程序bug。
在长期使用微前端的过程中我们也能发现其好处,业务代码再怎么发生改变,也不会影响整体系统的稳定性。而相比于微前端,微内核的设计抽象度会更加复杂一点,相对的,两者的交流也会更加频繁一点,自由度也会更加高。
相比于微前端固定位置,共享部分依赖的简单场景来说,微内核的核心系统会更加复杂一点。我们依旧是以 vscode 为例, vscode 需要抽象化他的核心系统,可以支持各种插件的功能,比如为系统的各个内容、token做标记,以支持各类主题的接入。为各种语言服务做抽象层,以兼容不同语言的需求等等。
这也是为什么这类做插件系统的应用很少。因为虽然大家都知道插件系统能够带来各种各样的好处,但是因为设计的复杂性导致愿意去做的人比较少。当然,这个复杂度是针对核心系统的,对于插件的开发者来说并不会感知到,而是可以直接使用成熟的核心系统提供的能力快速进行开发。相信开发过 vscode 的同学都不需要了解内核系统是怎么运作的。
当然,在日常的使用我们也有用到微内核的概念。常见的例子就是各类orm支持不同的数据库,然后我们通过一个适配层将通用的orm根据不同的数据库实现进行适配。
再比如飞书文档支持各类第三方内容块,而这些第三方内容块就是一个个插件。只需要统一的协议来约定交互行为即可。
所以为什么我说我们需要微内核架构呢?微内核架构更多的是一种设计思路,很多时候我们愿意去写集成式的应用,往往随着代码的迭代整个系统的复杂度越来越高、越来越难以维护。变成一个巨石应用,也往往被后来的维护者称为屎山代码。而如果我们前期就做好一定的抽象,那么随着时间而增加的代码复杂度的增长幅度也会逐渐趋于稳定。
那么有什么实现微内核架构的库呢
当然有。
mini-star(https://ministar.moonrailgun.com/) 就是一个可以满足想要构建微内核架构的库。
mini-star 只做一个微内核库该做的事情,即插件构建、加载、与依赖共享。
相比于微前端的基于路由的、同时只能运行一个子应用的限制,mini-star 并没有对开发者做任何的限制,也就是说并没有做任何预设的场景限制。如微前端因为其限制更多的还是用在后台应用上,而作为微内核库的 mini-star 则可以用在任何场景。
mini-star 提供了运行时加载器(runtime), 插件编译器(bundler) 和命令行工具(cli)。从全链路支持插件系统的开发。
编译生态
mini-star 的编译器依托于 Rollup 。因此可以直接复用现成的rollup生态对代码做优化。当然 mini-star 已经内置了一部分常用的编译插件,开箱即用。
懒加载
mini-star 的内核加载系统约定了插件和加载器运行时的规则,在运行时统一采用了类amd加载策略,因此依赖是可以收集以及被感知的,一个插件编译产物的结构如下:
源文件
1 | // 源文件: |
1 | // 编译后的文件: |
因此, mini-star 支持依赖懒加载,而如 qiankun、 garfish 这种使用webpack的external机制进行共享的微前端框架是不支持的。
1 | regSharedModule( |
更多的可以访问 mini-star 官网了解更多: https://ministar.moonrailgun.com/
利用 webpack-stats-viewer 分析 react-virtualized 摇树优化失效问题
背景
在项目性能优化过程中,发现 react-virtualized 依赖过重,经过初步分析是因为react-virtualized 虽然只是引用了部分功能,但是实际打包的时候将所有的代码都打包导入了。
我们起一个新的项目看一下。
在入口文件我们仅仅使用导入一个List功能。然后仅仅是打印一下,看看结果。
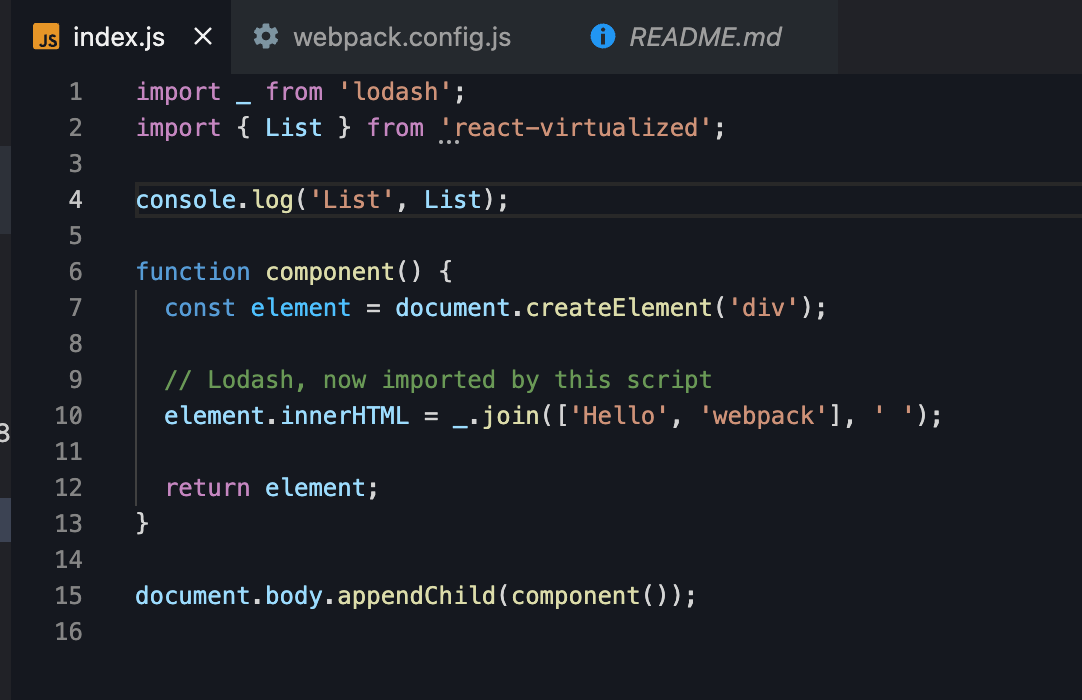

可以看到,通过webpack-bundle-analyzer 的分析,我们可以看到 react-virtualized 这个包被完全打包打进了产出中,尽管没有用到里面任何的东西。
了解 esmodule 这种打包方式的都应该知道摇树优化(Tree Shaking)。当我们通过 esmodule 的方式引入一个支持 esmodule 的包时,不被使用的包会被移除,以减少最终产物的体积。在react-virtualized 的路径中,我们可以很明显的发现我们引入的代码文件都是在 es 目录下的,这意味着这个包是支持 esmodule 的,尽管我们只用了 react-virtualized 这个包,其他不相关的代码依旧被打包进去了。
很显然,在 react-virtualized 这个库中,我们的摇树优化失效了。通过 webpack-bundle-analyzer 我们可以很轻易的看出这一点,然而更加深入的信息我们就不得而知了。
排查问题
为了解决问题,我们需要知道为什么会发生这样的事情,因此接下来我们要用到一个新的工具 —— webpack-stats-viewer-plugin
使用方式如下:
1 | npm install -D webpack-stats-viewer-plugin |
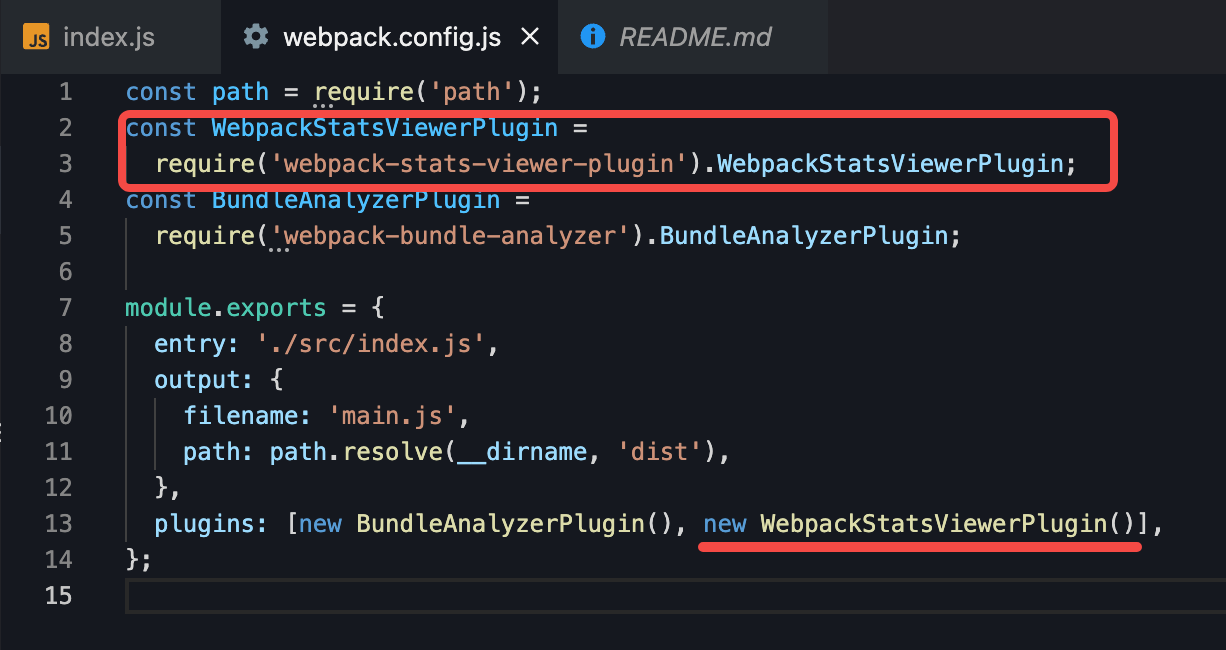
在每次 webpack 打包后,都会在输出目录生成一份打包报告。我们可以直接点开生成的报告看一下。大概内容是这样的:
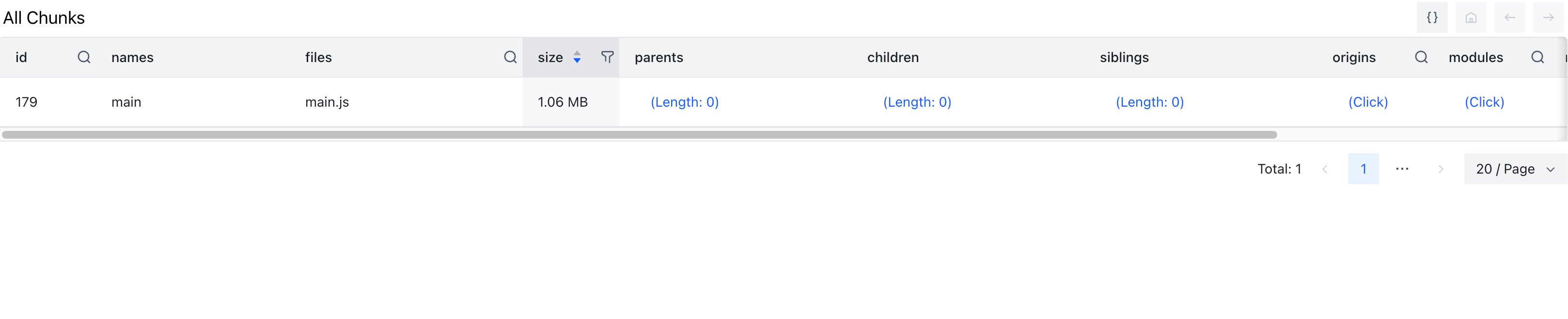
相比于比较注重美观的网格树来说,列表的显示更加直白与清晰。列表中的每个项都是一个独立的chunk, 列表显示了这个chunk打包出来的文件名,大小,以及chunk间的引用关系(父 chunks, 子 chunks, 和 同级chunks)。因为本例非常简单所以只有一个chunk,在这里我们要对单个chunk进行分析,在之前我们看到了 react-virtualized 已经被全部打进去了,所以我们要找到 react-virtualized 摇树优化失效的原因。这里我们点开 modules 功能看一下
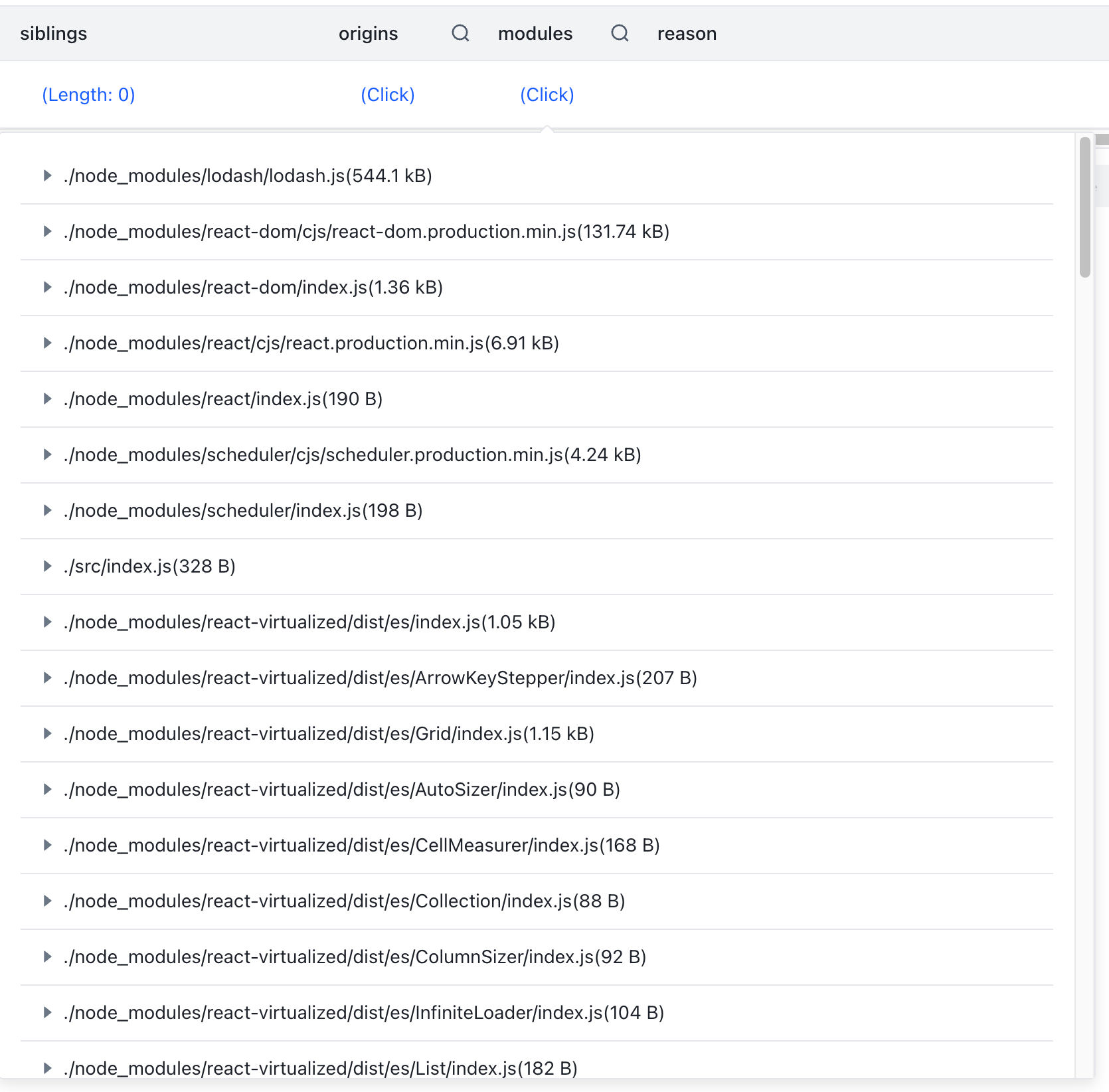
在弹出的popup中我们可以看到这个chunk包含的完整的模块列表,我们随便点开一个 react-virtualized 的模块
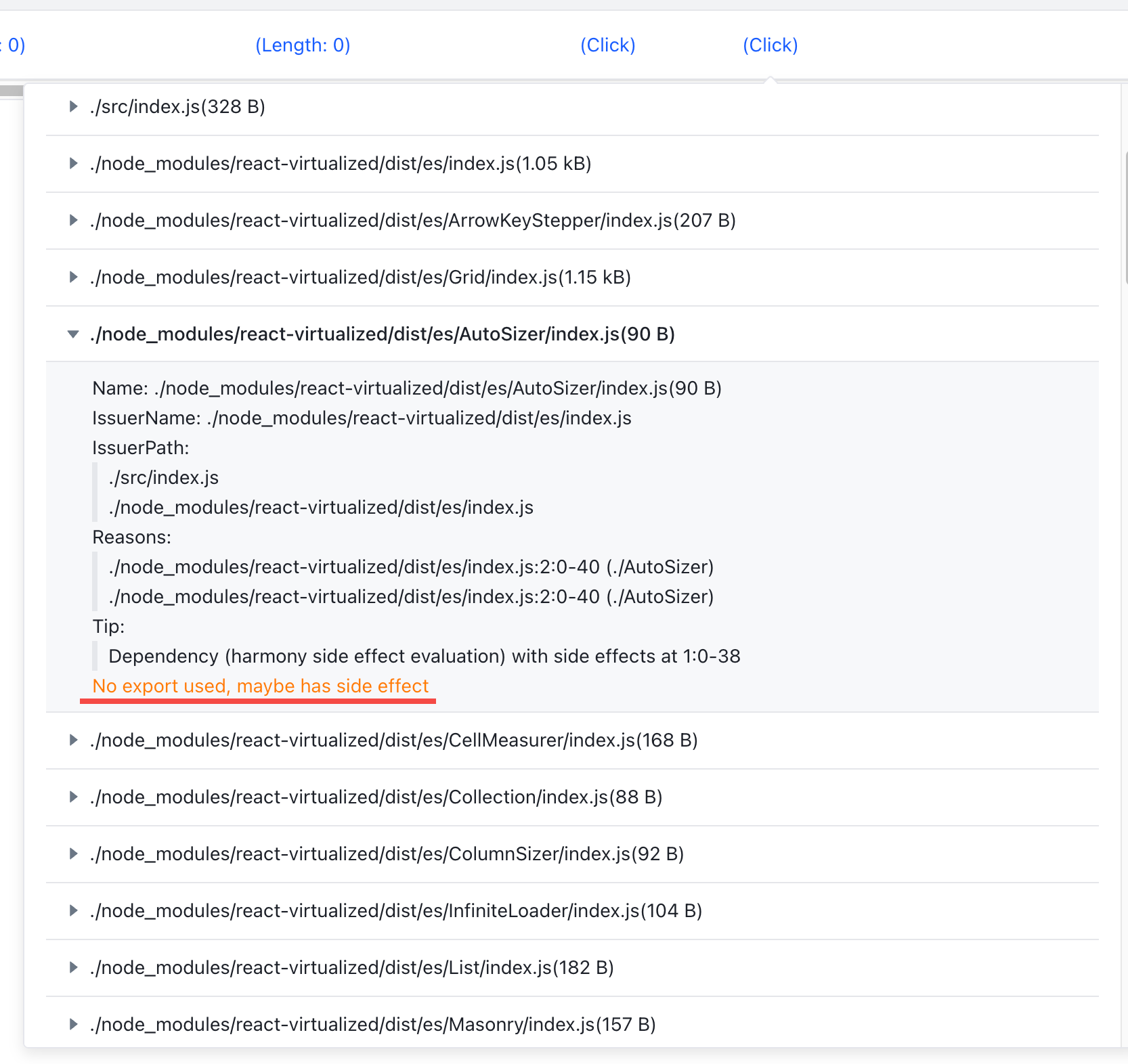
我们可以详细的看到一个模块的引用路径,引用原因,以及导入原因,以及一些优化建议。
需要注意的是黄色警告的内容,提示 No export used, maybe has side effect 。这就是我们主要要解决的问题,虽然这个模块提供了esmodule,但是却依旧会把所有的内容打包进去(尽管没有任何代码被引用)。
我们看一下这个文件, 在建议中提示我们第一行有副作用,我们进去看一下
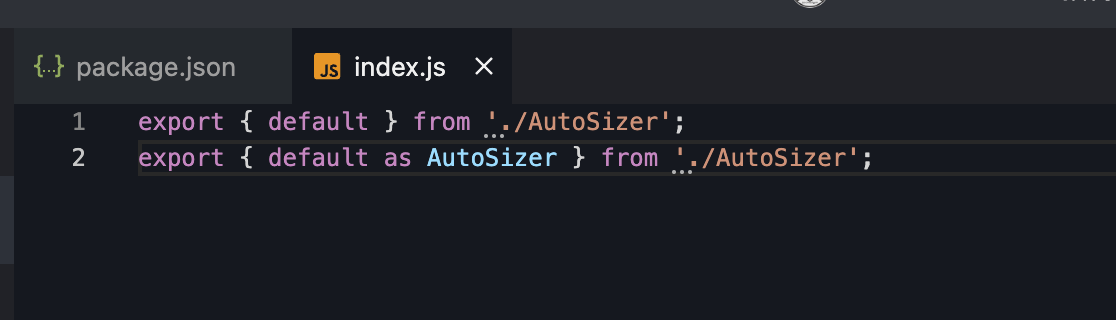
在这里的第一行是个默认导出,我们继续跳转进去看一下
按照工具给出的提示,我们可以看到这个变量声明是具有副作用的
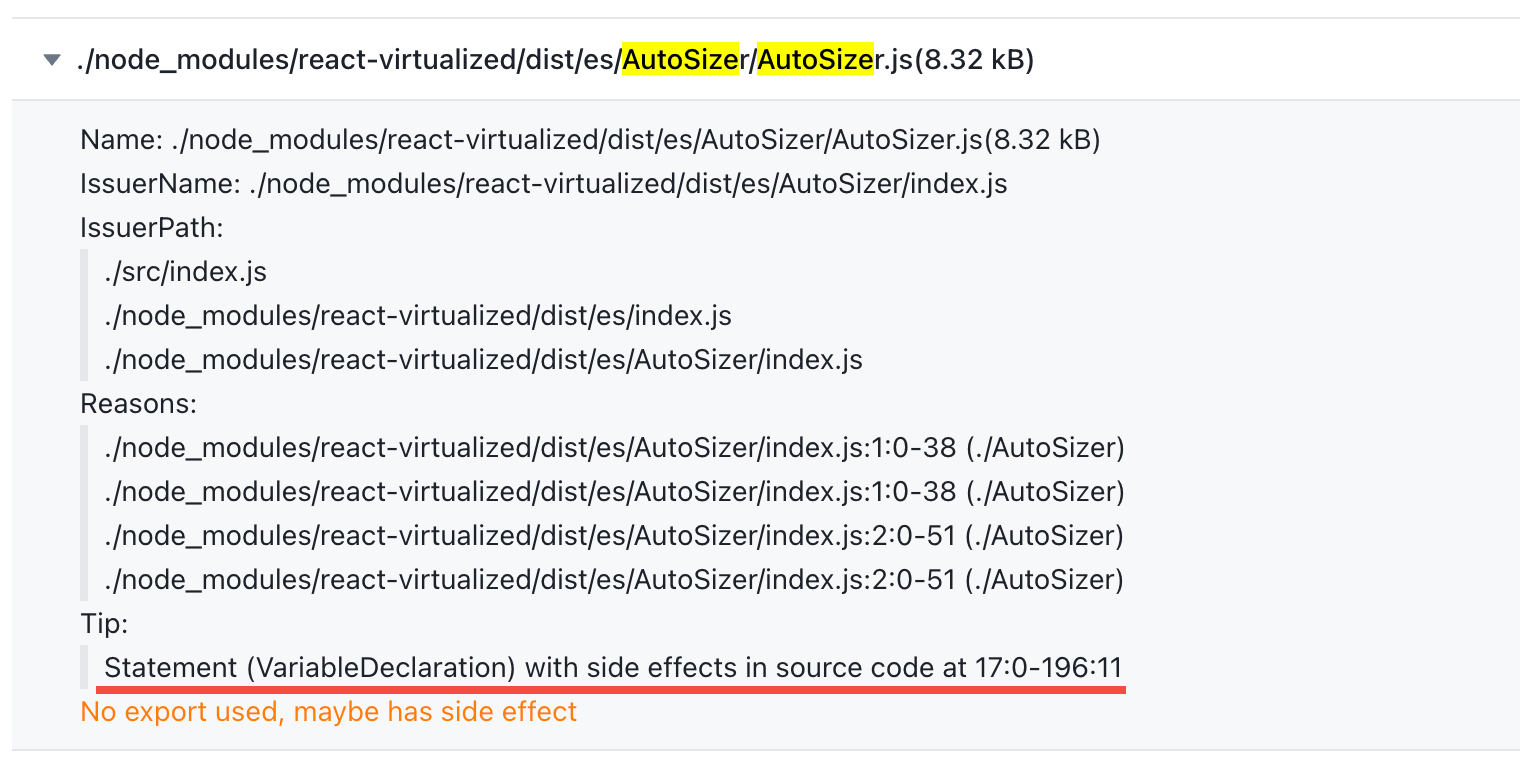
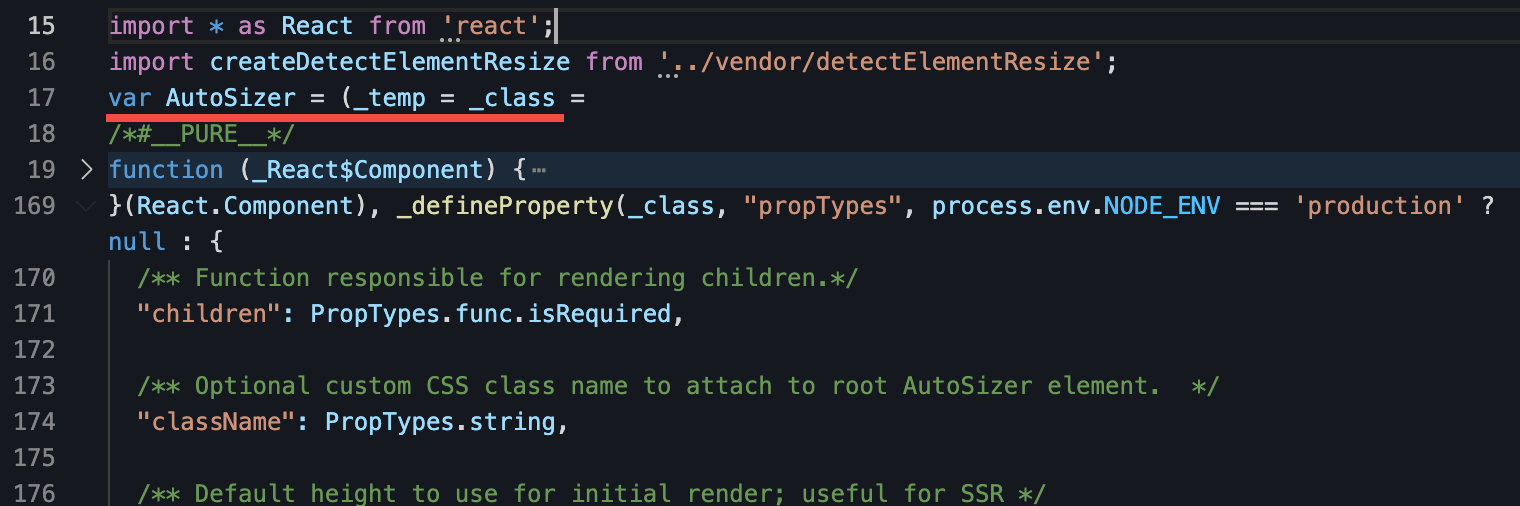
看起来是因为一个 /*#**PURE***/ 标记无法处理连续的赋值操作导致编译的时候失效。
另一方面我们可以很明显发现有一些编译时注入的代码,
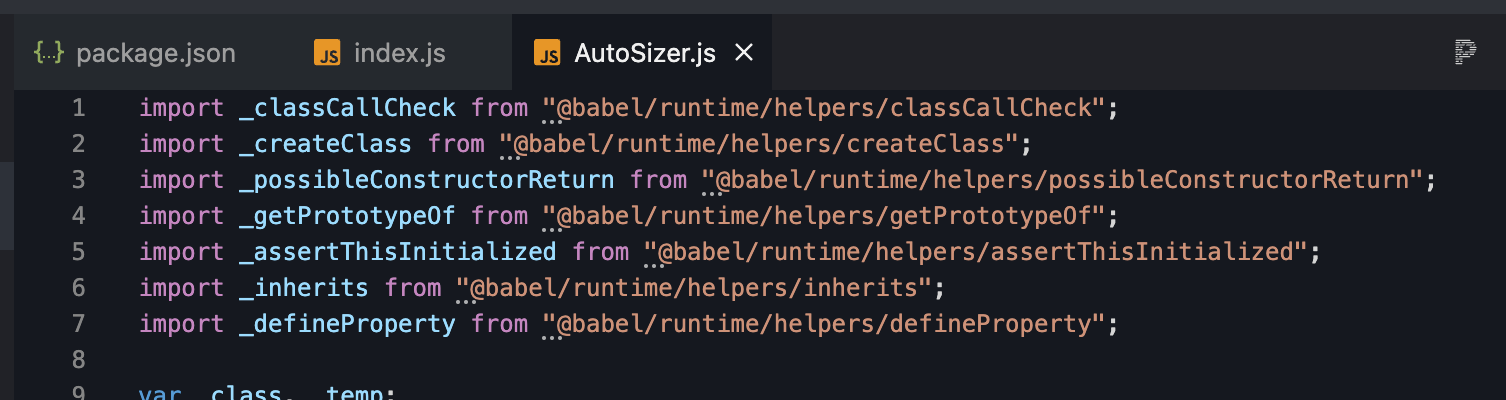
这些代码是编译时babel注入的polyfill,而当我们跳转过去看一下会发现这些内容不能满足esmodule的要求,require语法在摇树优化时会因为无法被正确的处理,为了确保整体代码不会出问题,因此webpack会把require所包含的内容一起打进去。
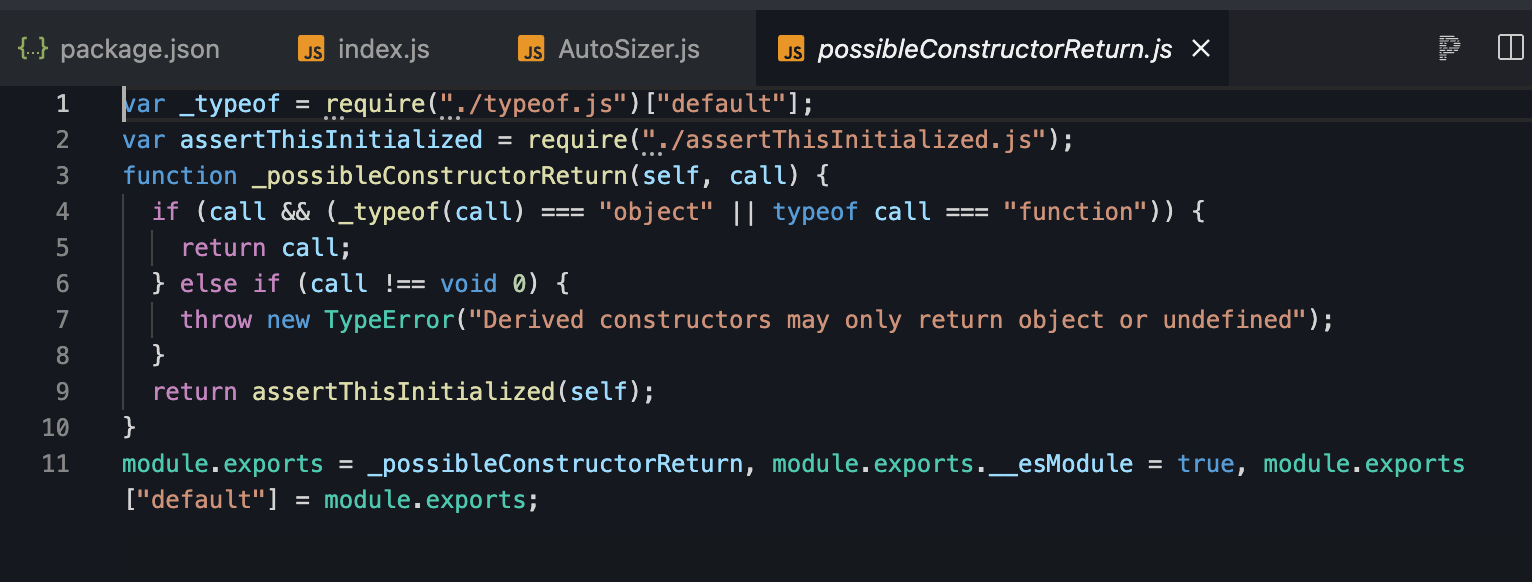
两方原因造成了react-virtualized 没有被使用的代码在引入时都被打包进去了,而类似的原因在这个库中到处都是。
这也难怪这个包的es 不生效了。
解决方案
解决方法很简单,就是直接通过es的引入方式来引入, 如:
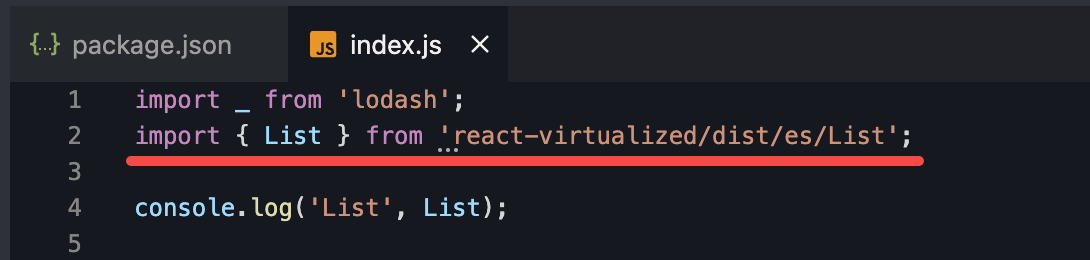


此时我们再看打包后的内容就干净了很多。
相关链接
演示项目: https://stackblitz.com/edit/github-rx5vpd
webpack-stats-viewer: https://github.com/moonrailgun/webpack-stats-viewer
React Query 简明设计哲学入门指北

Github https://github.com/TanStack/query 33k star
0x00 首先,为什么我们需要React Query
顾名思义,React Query 是一个请求库,但是这个命名并不准确,因为这个请求库本身并不处理请求 —— 他本身不会以任何方式向外发起任何请求。相比请求库,他更像是一个请求缓存层。
一个简单的使用大概是这样的:
1 | function Example() { |
相比于一般的在组件中发起请求,React Query通过 useQuery 帮我们自然而然的生成了一个请求中间层。
原始:

使用React Query后:

而从单个请求来看的话,似乎增加了这一层以后没有任何的收益
那么我们拓展一下呢?
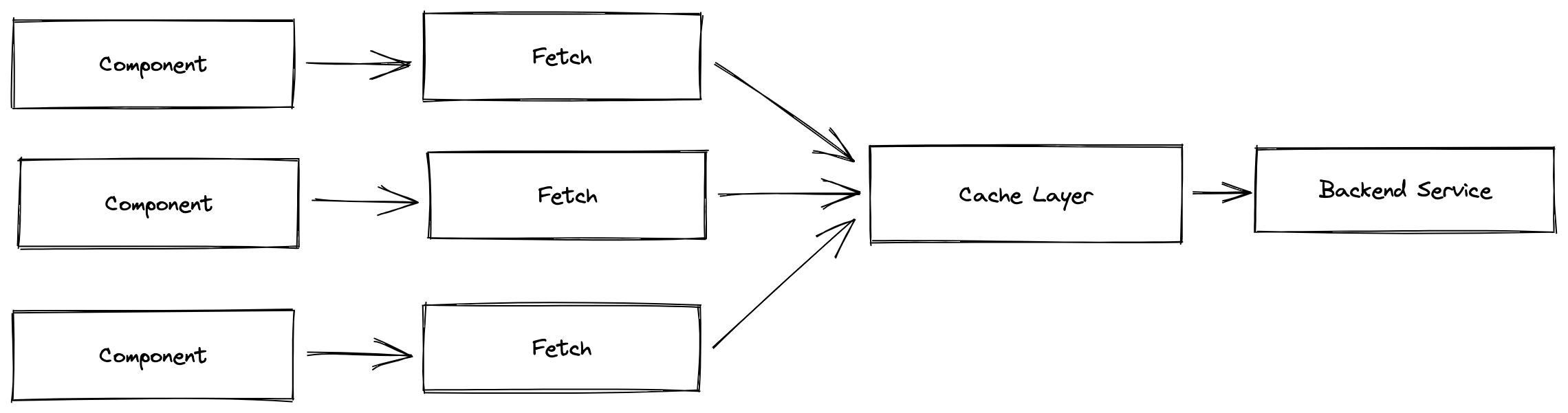
可以看到,通过一个中间的缓存层,我们可以把相同的组件同时发出的多个同样的请求合并成一个发送给服务端,这样对于服务端来说请求压力会减少很多。
但是,我们完全可以把相同的请求放在同一个地方,然后把结果传递给使用的组件,那么是不是就完全不需要面对这种情况了呢?
是的,我们在大部分时间做的就是这样的方式,很少会出现相同的请求发送很多遍的情况。但是这也是我要说的React Query通过中间层带给我们的最大的意义 —— 解耦。
想象一下,我们有以下这样的组件:
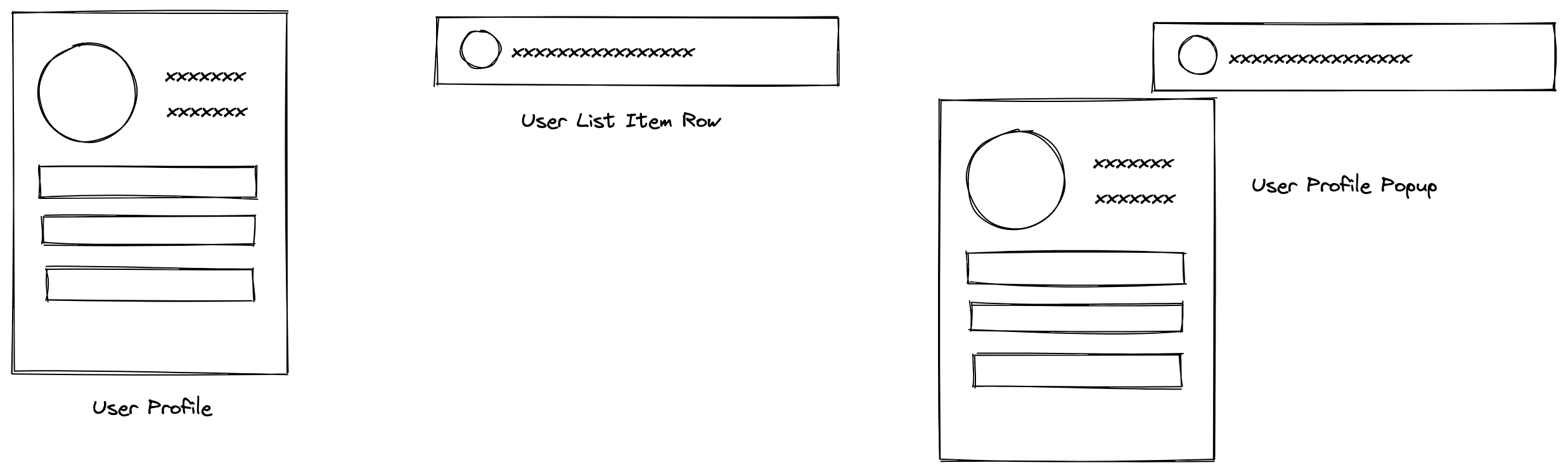
分别代表了用户信息组件,用户简单信息列表项,以及他们组合的产物。他们都需要获取最新的用户信息,用的是同样的接口。我们分别叫他们组件A,组件B和组件C吧。
当我们单独处理组件A和组件B时,我们只需要在组件挂载阶段去获取远程的数据即可。这非常容易,但如何我们将他们组件使用以后,一些问题就会出现了:我们不可能让他发起两次同样的请求,按照我们之前的做法,我们就需要在组件B渲染的阶段把数据拿到,然后在组件A弹出的时候将组件B获取到的数据传递进去。
这很容易,但是这也带来了上下文。即组件A既有自己获取数据的逻辑,又有根据上下文获取数据的逻辑。这种方式的数据管理是复杂的,难以维护的。
而通过React Query带来的缓存层,我们就无需关心请求的细节,每个组件都可以只关心自己的事情而无需关心上下文。所有的请求将会由一个统一的缓冲层来帮助我们统一管理请求数据。
0x01 数据活性
大家都知道,数据是有时效性的。在我们的HTTP协议中带来了一个新鲜度的概念,即在每次请求中标注一下一个请求的时效性,就类似食品的保质期一样。相比于缓存,我更加喜欢用数据活性这个概念,因为数据是有生命周期的。
在时效性有效的范围内,我们可以认为请求的资源是“新鲜的”,那么我们就可以在下次发送网络请求的时候不再向远程发送请求,而是使用本地记录的上一条结果。而如果请求的时间过了时效范围,那么这个请求将会被标记为“陈旧的”,那么再发起新的请求以后,就会真实的向服务器发送网络请求。这就是我们一般意义上的缓存。
而在service worker中, 有一种新的网络缓存管理概念,名为: Stale-while-revalidate
其意义上在于,在service worker代理网络请求的时候,为了确保用户每次都能非常快速的加载页面,sw会第一时间去从本地缓存中拿取数据返回给页面,但是同时在后台发送真实的网络请求去获取最新的内容并更新本地缓存。这样用户不会第一时间拿到最新的数据,而是以最快的速度打开页面,而在后台请求以确保下次的内容更新。
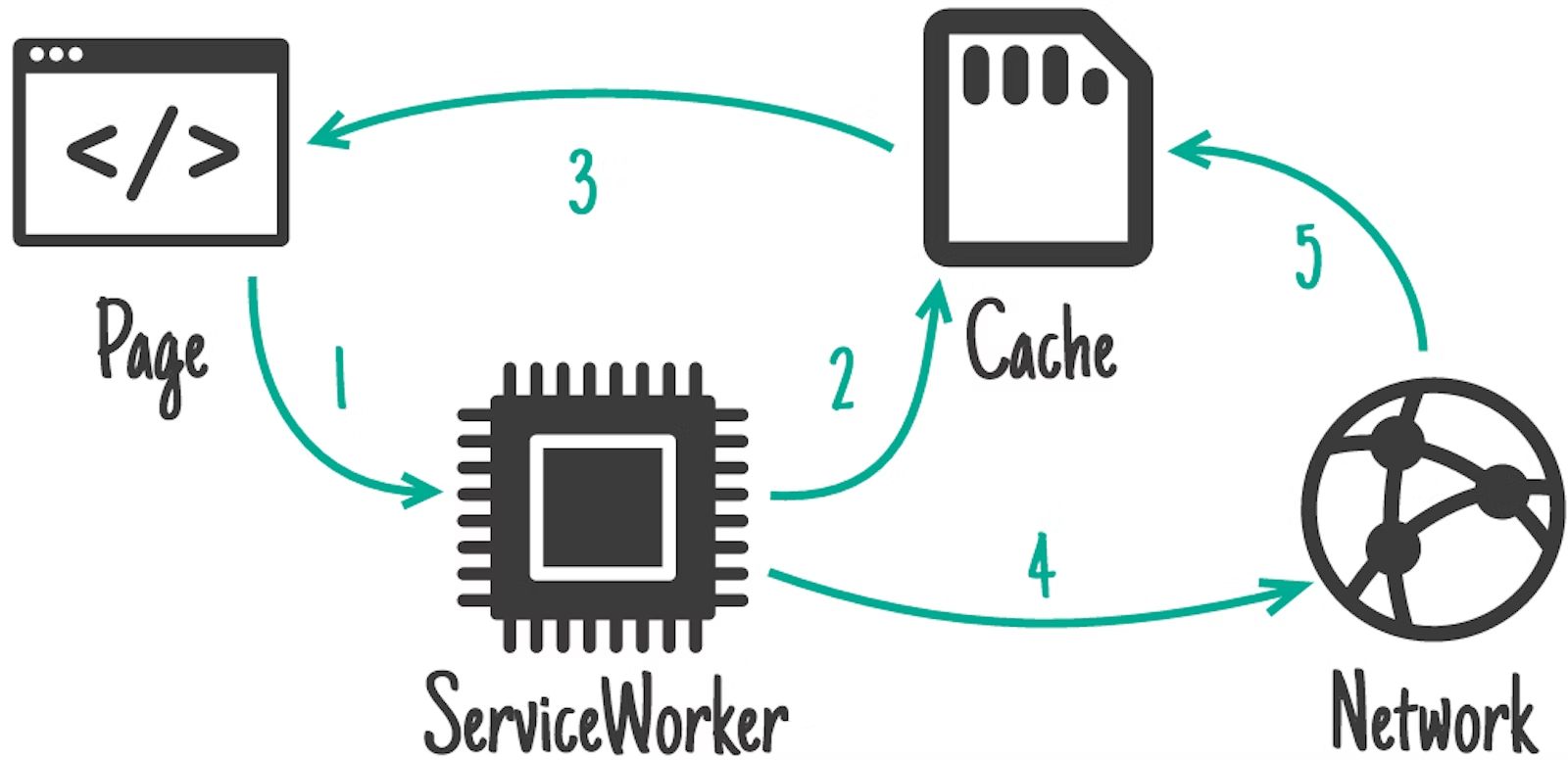
更多详细说明: https://developer.chrome.com/docs/workbox/caching-strategies-overview/#stale-while-revalidate
而React Query 在这方面做的更加好,相比于Promise的一次性的数据获取,hooks带来了允许主动发起的多次数据更新。这意味着React Query能做到更加复杂的数据更新策略。
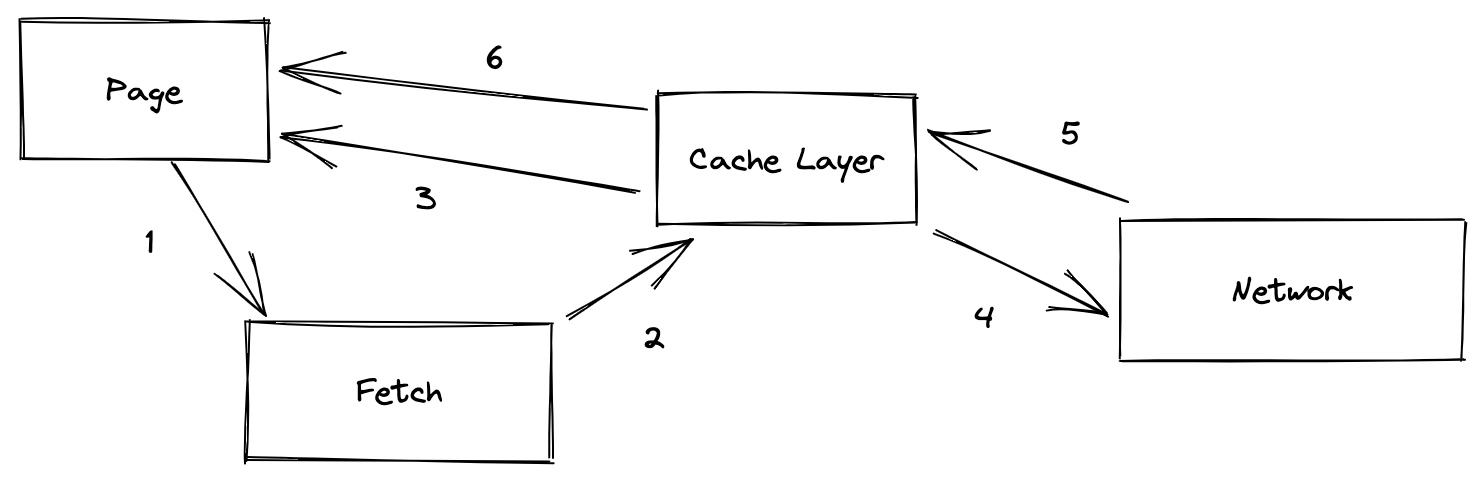
上图则是React Query在进行“陈旧”数据的处理方式,如果一条请求被标记为“陈旧”而不是“过期”,那么在 hooks 中,React Query会第一时间将旧的数据返回给前端,与此同时再向服务器发送网络请求,当网络请求的结果回来后,通过hooks 再一次更新数据。
对于标记的“陈旧”与“过期”的概念,就是在请求的时候定义的“slateTime” 与 “cacheTime”,区别就在于如果之前请求过,是否要第一时间返回到前端,然后二次更新最新的数据,还是选择直接等着网络的返回。可以看得出非常精确了。
同时,如果一个组件挂载后很长时间不更新,但是新的组件被更新数据以后,旧的组件也会同样更新保持数据一致性,用户在管理数据方面就没有任何压力了。
0x02 不仅仅是 react 与 query
坦白的讲,React Query的名字起的并不好。在我上面的讲述中大家可以发现,React Query做的其实并不是query的事情而是cache的事情,我们可以在其中管理任何的异步操作,比如一个高CPU的算法,比如一个与web worker的通讯结果。
另一方面,React Query 与 React 的关系在于他通过 react hooks 实现的数据响应式更新。然而其实什么方式并不重要,如果我们做一些抽象是不是能够作用到任何的数据驱动的框架中呢?事实上新版的React Query 也是这么做的。
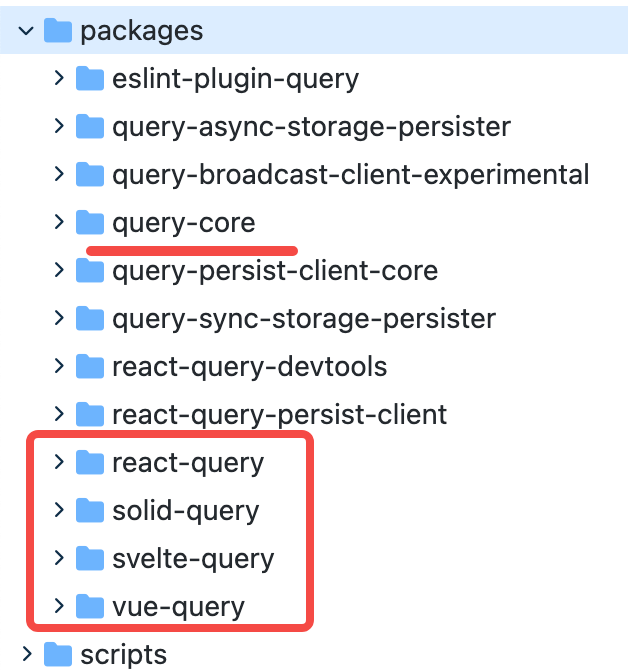
可以看到在新的结构中,拆分了内核包与各种框架的适配层。
这就是为什么我说他的名字起的并不好,具有很强的误导性。react query,即跟react无关,又与query没有直接关系。只能说历史原因难以修改,这也是为什么我在平时的工作中一直强调尽可能的减少技术负债,因为有的技术负债一旦背上可能就永远摆脱不掉了。
小即是美 —— 简约而不简单的状态管理工具zustand
我用过或了解过前端业界大部分流行的状态管理库。他们有的很复杂,有的很简单。有的用了一些深度改造的手段来优化细节,有的则是平铺直叙的告诉所有使用者发生了变化。在技术方案诡异多变与层出不穷的当下,只有一个状态管理库让我深深着迷,她极度精简到让我觉得不能再简单了,但是她也足够完备到应对任何场景。而我就一直在追究这样的一个宛如艺术品一样的状态管理库,经过一段时间的使用,我很确定她就是我的梦中情库。
她的名字叫 zustand
Github: https://github.com/pmndrs/zustand
极简定义
我们先看看其他业界的状态管理库的使用方式:
以比较主流的redux和mobx为例, 这里直接复制了官网的最小示例。
redux(@reduxjs/toolkit)
1 | import { createSlice, configureStore } from "@reduxjs/toolkit"; |
mobx
1 | import React from "react"; |
在 redux 中,我们需要先构建 reducer 来记录如何处理状态,然后根据reducer构建一个store。取值是通过store来获取,修改则需要通过 基于reducer一一对应的action来修改。
这样就确保了数据流永远是单向流动的: 即 UI -> action -> reducer -> state -> UI 这样的过程。其响应式的实现就是在执行action -> reducer的过程中收集到了变化,然后通知所有订阅这个store的所有人。然后订阅者再通过名为selector的函数来比对变更决定自身是否要更新。
如:
1 | const Foo = () => { |
我们再来看看另一派的实现: mobx 定义了一个 class 作为存储数据的store, 而对于数据的任何修改都是用一种类似原生的方式 —— 直接赋值来实现的。即既可以直接访问store中修改里面的值也可以通过调用store暴露出的方法来修改数据。而数据的取值也是直接通过最简单的数据访问来实现的。
看上去非常美好,但是这是通过一些”黑魔法”来实现的,当执行makeAutoObservable(this)的那一刻,原来的成员变量已经不是原来的数据了,已经变成了由mobx包裹了一层实现的 可观察对象, 即这些对象的赋值与取值都不是原来的含义了。这也就是为什么mobx可以实现reactive响应式的原因。
这时候我们再来看看zustand是怎么做的:
1 | import create from 'zustand' |
是的,只需要简单的一个对象就定义了一个store,不需要特意去区分是state还是action, 也不需要特意去构造一个 class 来做的非常臃肿。zustand 就是用最简单的设计去做一些事情,甚至其核心代码只有500行不到。
redux本身最核心的代码只有200行左右,但是如果要在react中使用需要加上
redux-react和@reduxjs/toolkit就远远超过了
另外可以注意到的是,zustand天生设计了一种场景就是react环境。其他”有野心”的状态管理库往往是从 vanilla 环境(纯js环境)开始设计,然后增加了对react的支持,可能后续还会增加其他框架的支持。但是zustand则不是,天生支持了react环境,然后基于react环境再衍生出vanilla环境的支持。
那么很多人就会好奇,既然都支持vanilla和react,那么从哪个环境开始设计有什么区别么?
答案是有的,从不同的环境开始会从底层设计上就带来很大的偏差,最后落地到使用方来说就是基本使用需要调用的代码、运行时以及复杂度的差异。在我过去的开发经验告诉我这样是正确的,我几乎没有看见过哪个库能同时在多个框架中都能如鱼得水的。不同的框架会有不同的生态,而哪些特有的生态则是最贴合的,如redux之于react,pinia之于vue, rxjs之于Angular。很少有哪个库能够在多个环境中”讨好”的。因此zustand就一种非常聪明的做法,专注于一点非常重要。
那么回到zustand的基本使用,我们可以看到zustand通过create导出的是一个 react hook, 通过这个hook 我们可以直接拿到store里面的state和action,非常类似于redux的useSelector。不同的是不需要dispatch来推送action, 也没有任何模板代码,数据类型天生区分了state和action, 只需要最简单的调用即可。
相比于mobx, 也没有什么”黑魔法”, 简单而不容易出错。而且也不像mobx会因为依赖class实现的store而引入天然的问题(比如作为数据store不应该有生命周期,而class的constructor天生就成为了生命周期的一种)
人的恐惧往往来自未知,
mobx的对象就是这样的一个黑盒。这就是我不怎么喜欢mobx的原因
那么,怎么应用到所有场景呢
zustand是一种非常简单的实现,简单到让人觉得是不是总有一些场合是无法覆盖到的。而这就是我觉得zustand是一件艺术品的原因。因为他总有巧妙的方式来不失优雅的适配任何我想要的场景。
在纯js中调用? 可以
1 | useBearStore.getState() |
通过getState方式就可以获取最新的状态,在使用的过程中需要注意这是一个函数,目的是在运行时中获取到最新的值。里面的数据不是reactive的。
想要有作用域? 可以
1 | import { createContext, useContext } from 'react' |
与原生 react 的 Context结合就能实现作用域的效果。并且进一步将store的创建合并到组件中,也能获得组件相关的生命周期。
想要在不同的store中相互调用?可以
通过useBearStore.getState() 就能实现store间相互调用。当然需要注意管理好store间的依赖关系。
想要中间件? 没问题
zustand 的库自带了一些中间件,其实现也非常简单。参考zustand/middleware的实现可以学习如何制作zustand的中间件。
想要处理异步action?没问题
在redux早期,想要做异步action是非常头疼的事情,而rtk出来后会稍微好一点,但是也很麻烦。而在zustand,可以非常简单
1 | const useFishStore = create((set) => ({ |
不足与思考
再好的设计如果不加限制也会出现 shit code。想要把 zustand 这样小巧而精美的库用好而不是用坏需要一定的技术管理能力。盲目的去使用新的技术并不一定能给技术团队带来一些收益,但是可以带来新的思考。
另一方面,zustand 是一种全局store的设计,不能说这种设计不好,但是也意味着带来了一种比较经典的技术难题,即依赖管理。当项目中出现相互依赖的时候,如何管理,怎么确保在后续的维护中不构成污染,在调试时不会引入噪音。这是我认为所有的全局store都会面临的问题。
谈论从把多项目合并成一个项目中获得的收益
在开源社区流行着这样两种项目管理的方式:
- 多repo仓库管理 (multirepos)
- 单repo仓库但是多包管理 (monorepos)
在很早的时候, 我的项目 tailchat 是一个典型的多repo管理的项目。
我创建了一个组织,组织下有多个tailchat相关的项目:
- tailchat
- tailchat-server
- tailchat-website
- tailchat-cli
- tailchat-rss-bot
- tailchat-archive
- tailchat-docs
- tailchat-meeting
- …
多repo的好处在于绝对的隔离,独立的发布机制,独立的仓库上下文(issues/prs)。但是我在长期的时候中逐步发现了多repo管理上的问题,以至于我抽出了时间将其合并成了一个项目。
接下来我会说说我遇到的问题。
多repo遇到的问题
精力上的分散
多repo意味着要同时管理多个项目,一些边缘的repo甚至会长久的失去维护。对于开源项目来说失去维护意味着死亡。而开源项目也往往会意味着管理人员精力上的分散,不论是企业支持的开源项目来说还是个人支持的开源项目来说。
比如react社区知名的UI组件库 antd。作为一个热门库来说它一直保留着非常高的活跃度,也不缺少维护人员。但是他的基础库rc-xxx却很少有人去处理pr。因为摊子铺的很大,十几个小的组件库分成不同的repo,就意味着开发组的成员很难分配精力在这些改动并不频繁的仓库上面。
发版与分发上的割裂
以最基本的前后端分库来看(client/server),两个repo意味着两套发版流程(当然可以说通过第三方平台把他们组合在一起,这个我们暂且不讨论)。同时意味着你不得不打两个tag,发两个release,以及跑两个CICD流程。如果你有一个website项目(文档)。你不适合放在任意一个client/server 仓库。这不得不造成你必须再创建第三个项目。
这三个项目从逻辑上来看确实是没有任何关系,但是在业务上来看却是耦合在一起的!这三者的同步就意味着需要花费维护者额外的精力,也意味着风险。
产物困难
另外就是项目的产物,多repo意味着多产物。多产物也意味着用户需要更多的上下文,对于不了解或者不愿意了解的用户来说这就是额外的错误可能以及精力成本。额外的入门门槛会极大的打击用户的使用信心。
一个简单的例子就是,作为用户更加希望只需要部署一个应用就能完成一切。而一个需要 前端+后端 的项目意味着额外的学习成本,不友好。
基本配置不通用
多repo的管理机制还有一个常见的问题就是项目的配置没有办法通用。比如 Tailchat 项目是使用 typescript 来进行开发的,还需要一些自动化工具比如代码格式化,代码检查,git hooks等。那么一个项目需要配套: tsconfig.json, commitlint, prettier, eslint, lintstage, editorconfig…
多个项目就要配多套配置。如果改了一处需要把所有的项目都改一遍。想想就简直是一场噩梦!
当然可以产出一套工具专门管理相关的配置,但是这也意味着额外的精力成本,同时也引出了另一个问题,那就是改动的滞后性 —— 改动的配置没有办法立即产生效果,必须提交代码到这个工具的仓库 -> 发布 -> 同步到所有相关的仓库中。
如果说我们花了太多的时间在这种事情上,那我可以认为,这个项目的DX(Developer Experience) 是失败的。
贡献的积极性
另外一个比较隐晦的问题在于,对于开源项目来说,多个包往往也会打击潜在贡献者的贡献积极性,贡献者往往期望往主库去提交代码,而多库意味着贡献的分散化。
使用 monorepos 结构后我获得的收益
自从将原来的项目结构修改为monorepo以后,写代码都舒服了很多。其中立即能够获得的收益包括但不限于:
- 依赖缓存复用
- 一套配置所有项目受益
- 统一管理所有 action 和 action env
- 产物统一,只需要输出一个docker镜像
- 用户也反馈部署更加方便了
- 统一版本号,不会再出现前端一个版本后端一个版本的情况了
- 打开项目更加方便了,不需要打开多个repo
- 只需要关注一个项目的 github webhook 就可以订阅所有动态
同时,其他一些可能的操作也变得有可能了,比如:
- 编写脚本,从客户端与服务端的代码中收集信息自动生成文档。
- 客户端根据服务端代码自动生成网络请求代码
- …
当然,有受益就有付出,monorepos 目前给我带来的问题有:
pnpm install的时间更长了,因为需要安装/编译的内容更多了docker build的时间更长了,因为每次打包都需要同时编译前端和后端的项目,而不管有没有发生修改。node_modules的内容过多导致在tree viewer中翻页会比较困难。
我觉得这些问题都是可以接受的,相比收益来说这点付出几乎可以说是忽略不计。当然这只能说是个人开发者或者小团队开发能够有很大收益的方式,对于大型团队来说,monorepos的方式会带来很高的沟通成本和管理成本。只能说存在即合理,作为开发人员我们需要找到适合自己的当前状况的最优解。
webpack 打包分析 —— 通过分析工具优化体积问题
背景
众所周知现在前端代码的体积越来越大,虽然网速也上去了但是还是跟不上业务膨胀的速度。而vite还比较年轻,大部分的项目依旧还在使用webpack进行打包。
而另一方面webpack也确实在精细优化上有足够的优势。在对代码结构做深度分析与优化的时候也有非常不可替代的作用。
开始优化
而我的项目也非常久违的没有观察过打包内容了,因此我决定久违的看一眼。
在优化代码之前,我们需要找到问题。通过官方推荐的 webpack-bundle-analyzer 来输出打包体积图
用法:
1 | if (process.env.ANALYSIS) { // 任意环境变量, 确保仅正常打包不输出分析报告 |
打包后自动打开网页展示如下内容:

一眼就看到三个大块的包,其中 all.json 和 twitter.json 两个包都是懒加载的,可以理解,但是为什么 vendors 中的 lodash.js 这么大?我一眼看出你小子不对劲!

放大看一眼,好家伙,一个包占用500多KB, 比antd还要高。而且 lodash 中并不是所有的函数都会被使用的,不应该整个包被打进来。
我们用 webpack-stats-viewer-plugin 来对其进行进一步分析
用法:
1 | if (process.env.ANALYSIS) { // 任意环境变量, 确保仅正常打包不输出分析报告 |
找到异常的那个 chunk
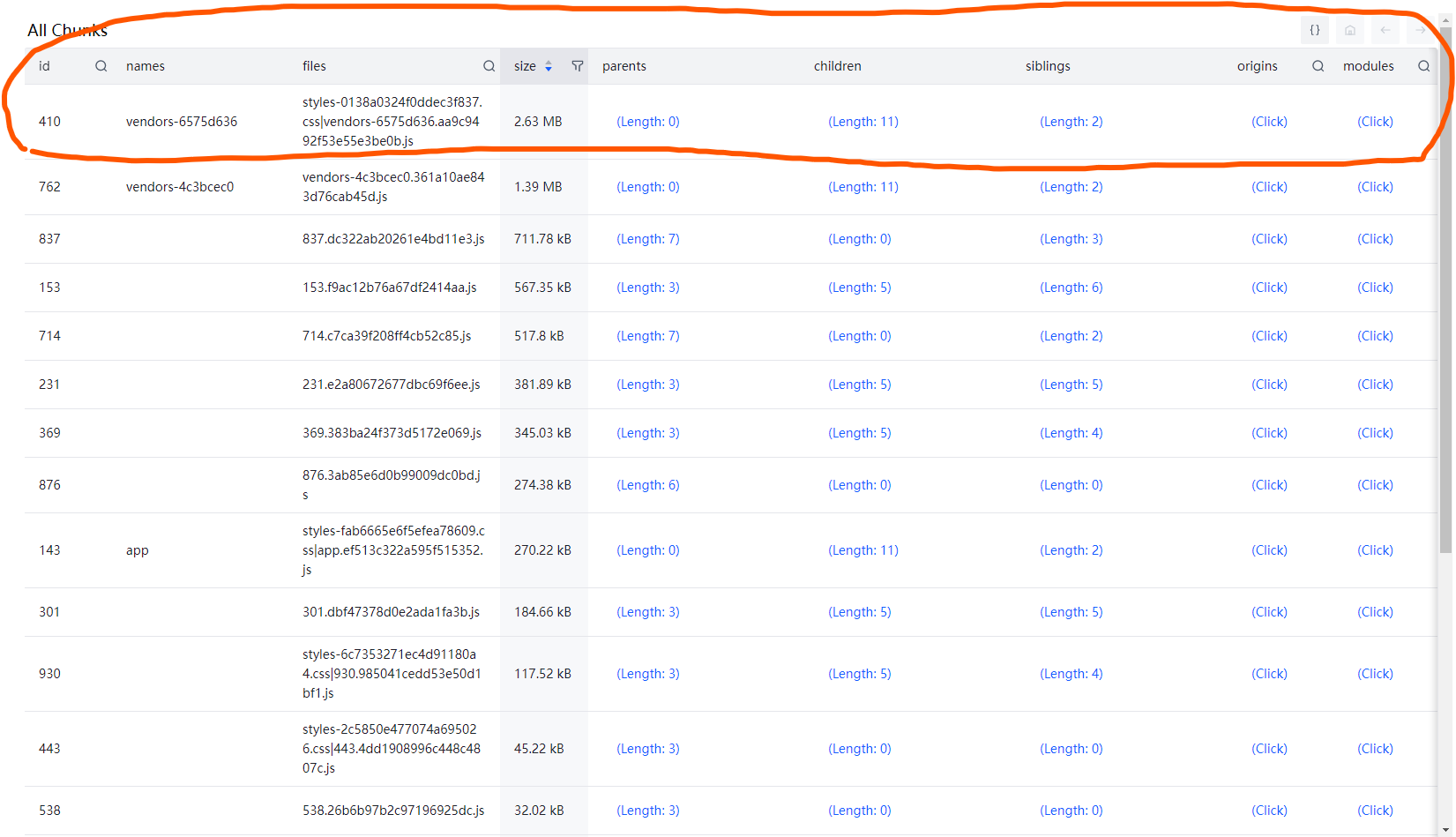
点开右侧的 modules 中找到 lodash
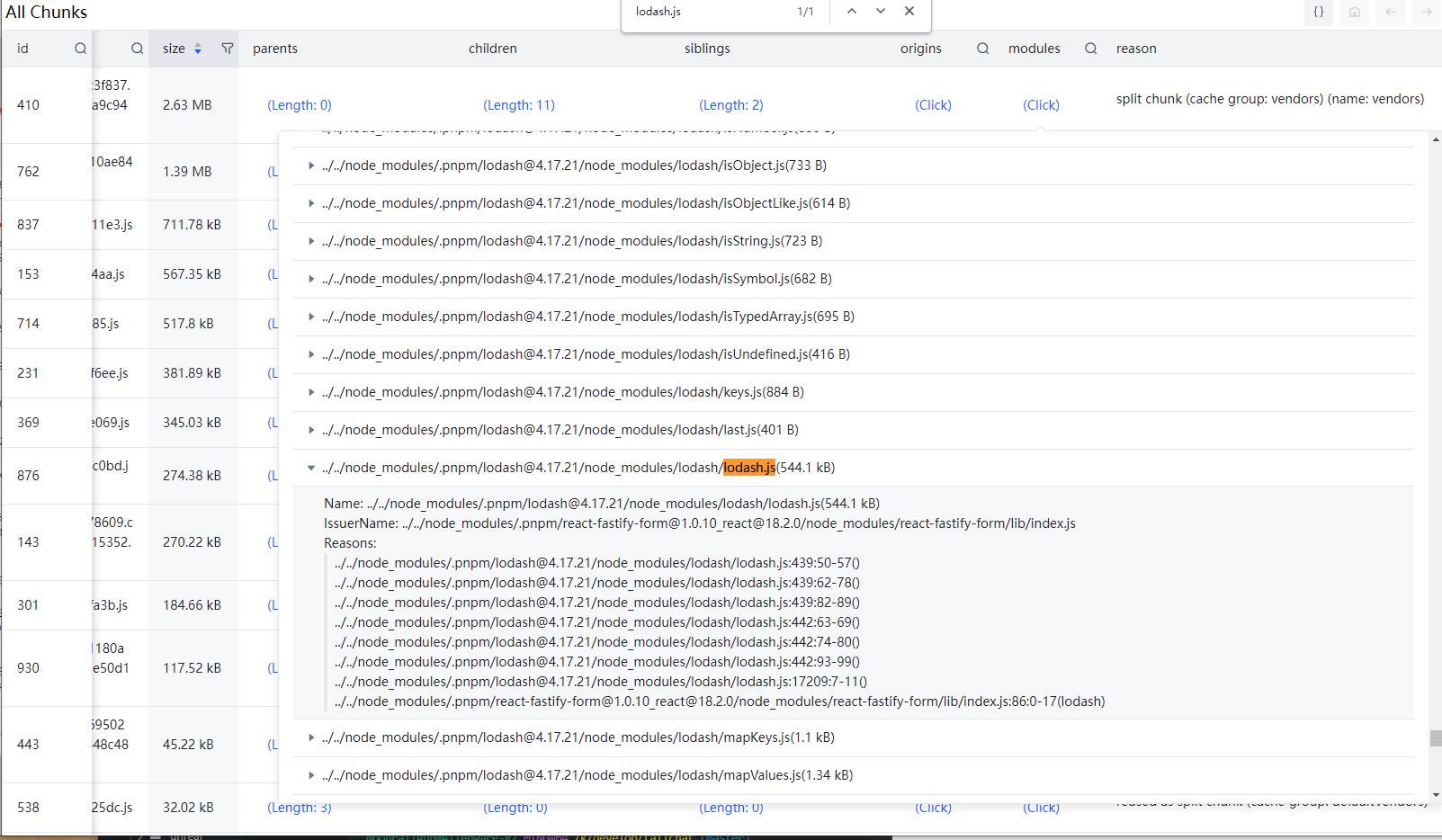
通过 webpack-stats-viewer-plugin 的进一步分析我们可以很清晰的看到这个包是被 react-fastify-form 引入的。
我们看一下源码:
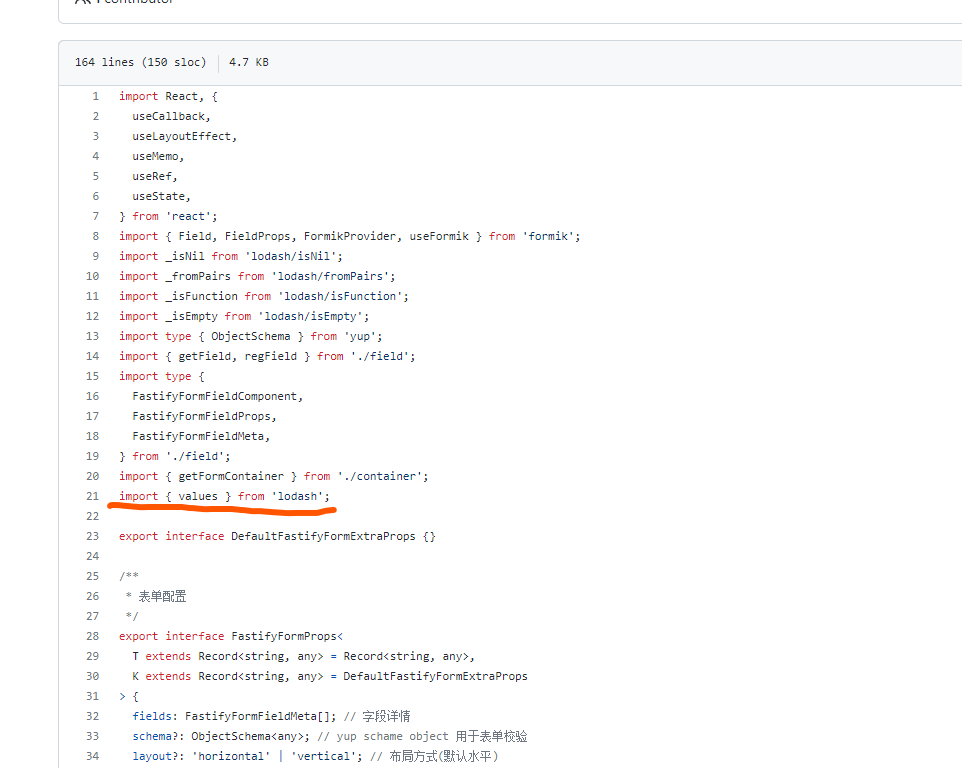
果然,在代码中其他地方都是使用 lodash/xxxx 引入的,而在划线这行却直接把整个包引入了进来(可能是因为),而lodash这个包本身不支持esmodule, 因此导致lodash整个包被打入,白白多占了500多KB的依赖。要知道总共也就2MB!
那么找到原因就好修了,直接修改源码 -> 重新发布 -> 更新依赖一气呵成。
验收成果
最后让我们看一下修复好的成果:

瞬间少了一大块体积。可见能够利用好工具可以帮助我们更好的对 webpack 的产物进行优化。
元编程快速入门
什么是元编程(Metaprogramming)
一言以蔽之,元编程就是通过代码实现代码的一种方式。
在一般情况下,我们写的代码是直接对应的业务逻辑的。在一定程度上可以说是”所见即所得”的。这种代码是最符合直觉的。但是在某些情况下,正常的代码会显得不是非常高效。因此我们需要通过用代码来生成代码的方式来开发,这就是我们所说的元编程。
为了更好的理解元编程,我们来用一个非常简单的例子来说明一下元编程:
我们需要生成一些假的电话号码,用一般的代码可能会是这样实现的:
1 | const mobilePool = ["18012345678", "18112345678", "18812345678"]; |
不论这个函数如何调用,都是从一个有限池(代码)中获取的某一项内容。但是实际上这种方式是比较受限的,因此以元编程的思想来说,我们可能会写出这样的代码:
1 | const mobilePrefix = ["180", "181", "188"]; |
即我们设定一个规则: 一个手机号是以 180,181,188 开始的, 然后后面跟上 8 位任意数字的,均视为一个合法的手机号。
其元信息为: 手机号是一个以固定3位开头加8位任意数字组合而成的11位数字。
那么我们就可以根据这种固定的规则生成无限(相对手写)种可能的手机号码。
当然,相信大家都能写出代码。元编程也不是什么比较新鲜的东西,大家可能都写过类似的东西。元编程的思想对于我们来说也是一种必须掌握的编程能力。
元编程能做什么
当然上面的 case 过于简单,甚至可能都不能算得上元编程。元编程的概念在很多比较底层、基础的场景是非常常见的概念。
比较常见的场景是:
- 编程语言(比如 typescript, coffee)
- 框架语言(比如 jsx, vue-template 等)
- 低代码/无代码平台
- 后端 CRUD 框架(比如 graphql)
- 各类 linter, formatter, parser, transformer, generator.
- …
在平时开发中,我们常用的 antd 的 Table/Column 这种形式的代码也是一种元编程方式, 而 Form 则是普通的编程方式
如何实现元编程
我们通过来写一个元编程的表单来简单说一下元编程的实现。
在普通的表单中,我们的组件可能是以下这样的:
1 | function App() { |
这是一个简单的用户注册表单, 为了多样性我还增加了一个desc属性用于描述用户的记录。
好的,那么如果用元编程的思想去看待这个问题呢?我们把 “渲染” 和 “数据” 分开考虑:
- 这个表单有以下字段:
- username
- password
- desc
- 一个表单可能有以下类型:
- input
- password
- textarea
然后通过组装可以变成一个数据结构:
1 | const meta = [ |
这个就是一个元数据,用于表达想要去渲染的界面是怎么样的一个结构。
当然,仅仅有数据还是不够的。因此我们还需要一个通用的组件来将这个元数据转换成实际的渲染视图。
那么这个组件的接口应该是这样的
1 | <MetaForm meta={meta} onSubmit={handleSubmit} /> |
这个组件接受一个meta对象用于”填充”内容,返回一个点击提交按钮的回调来告知外部
我们来实现一下:
1 | const MetaForm = ({ meta, onSubmit }) => { |
以上就是一个非常简单的元编程的表单组件,后面想要的话还可以自定义type实现, 增加更多的属性, 增加校验规则等等。。而在一个完善的元编程的架构下,开发是非常迅速的。
作为开发,我们只要能够掌握元编程的思想,对我们对于开发的架构思想是非常有帮助的。