exportconst provider = reactBridge({ el: '#root', // 此处的root是子应用自己声明的root // a promise that resolves with the react component. Wait for it to resolve before mounting loadRootComponent: (appInfo: AppInfo) => { returnPromise.resolve(() =><RootComponent {...appInfo} />); }, errorBoundary: (e: any) =><ErrorBoundary />, });
// Put the lifecycle plugin at the end, so that you can get the changes of other plugins this.usePlugin(GarfishOptionsLife(this.options, 'global-lifecycle'));
// Initialize the Garfish, currently existing environment to allow only one instance (export to is for test) functioncreateContext(): Garfish{ // Existing garfish instance, direct return if (inBrowser() && window['__GARFISH__'] && window['Garfish']) { returnwindow['Garfish']; }
const GarfishInstance = new Garfish({ plugins: [GarfishRouter(), GarfishBrowserVm(), GarfishBrowserSnapshot()], });
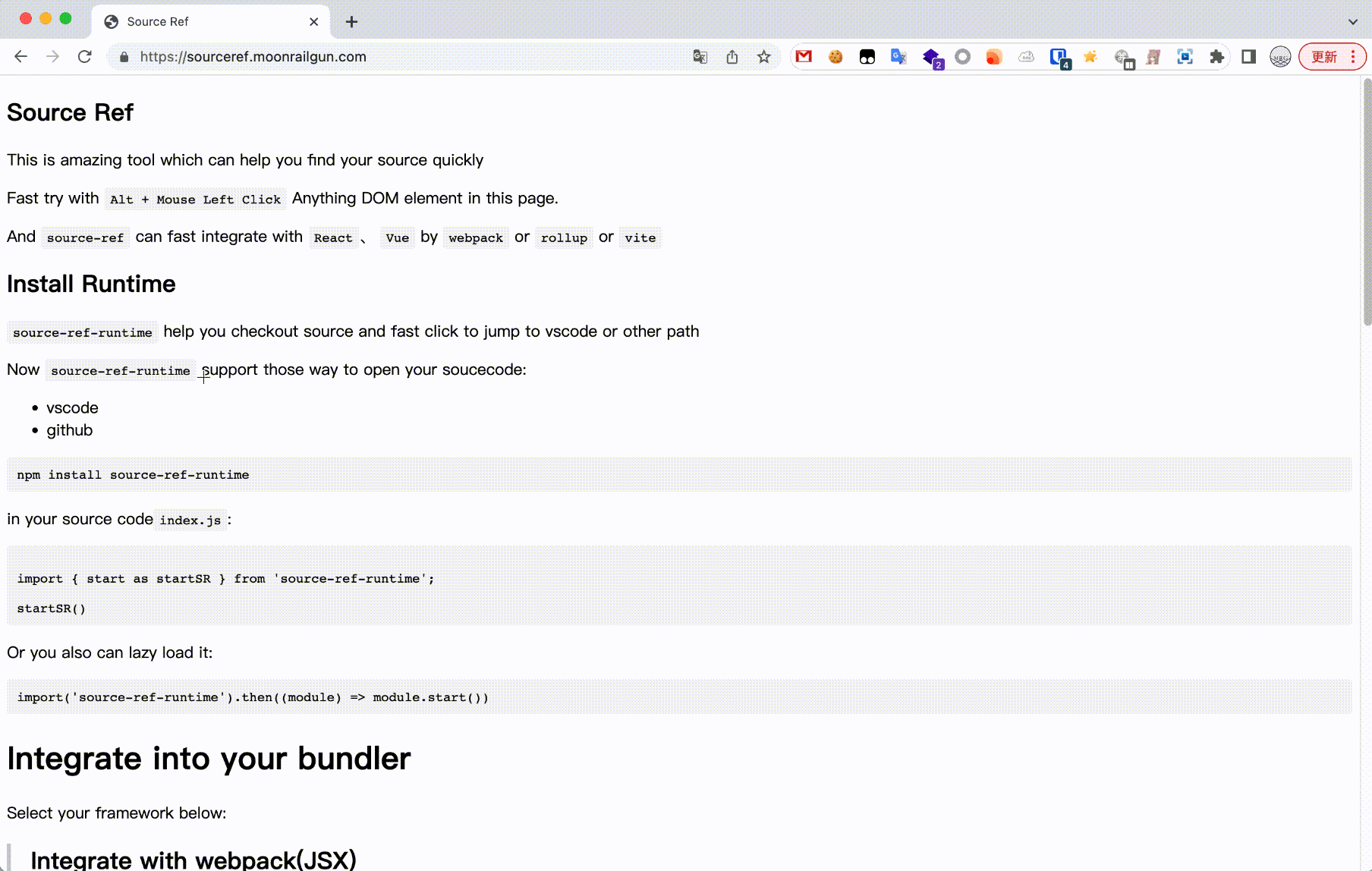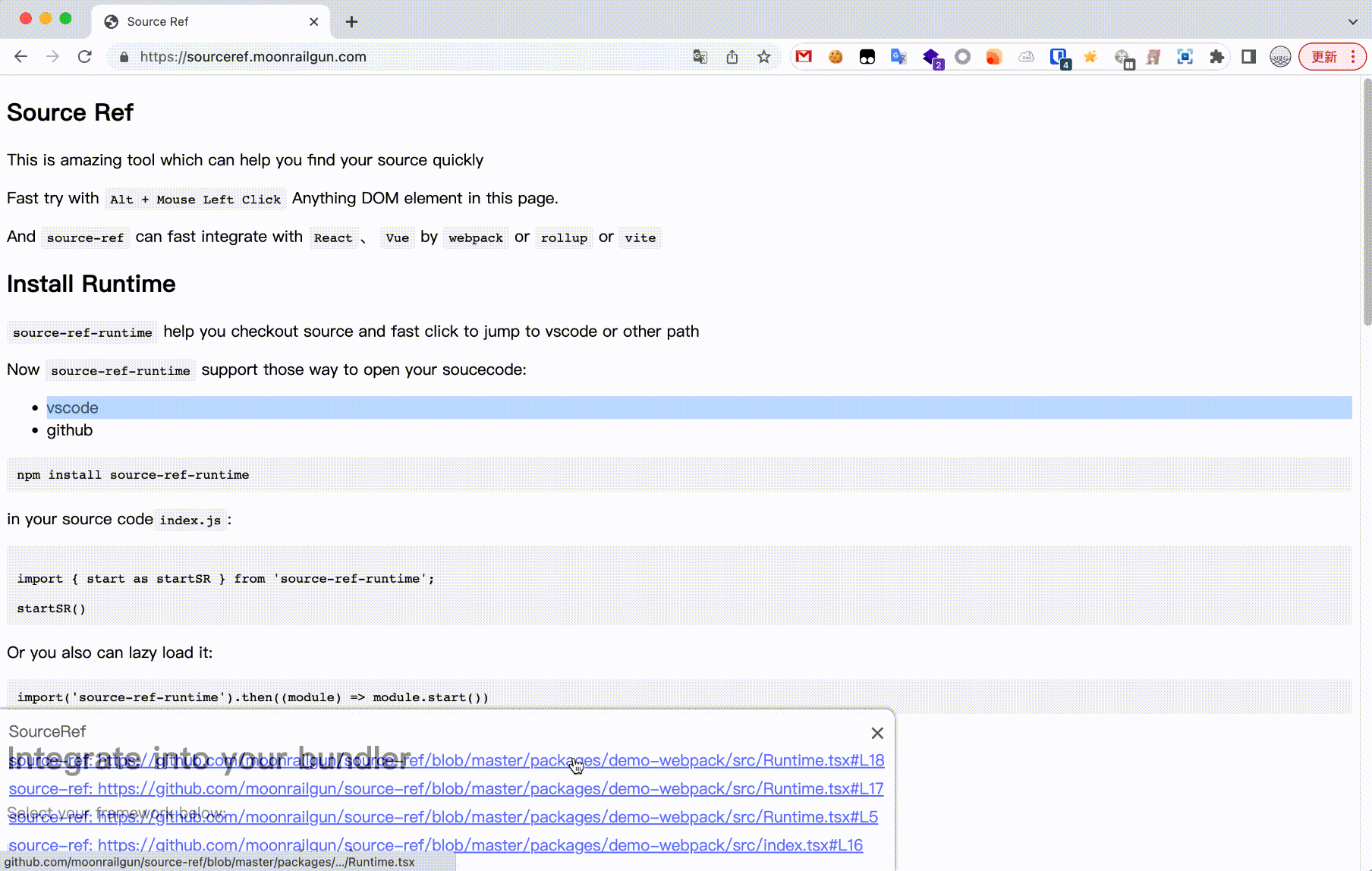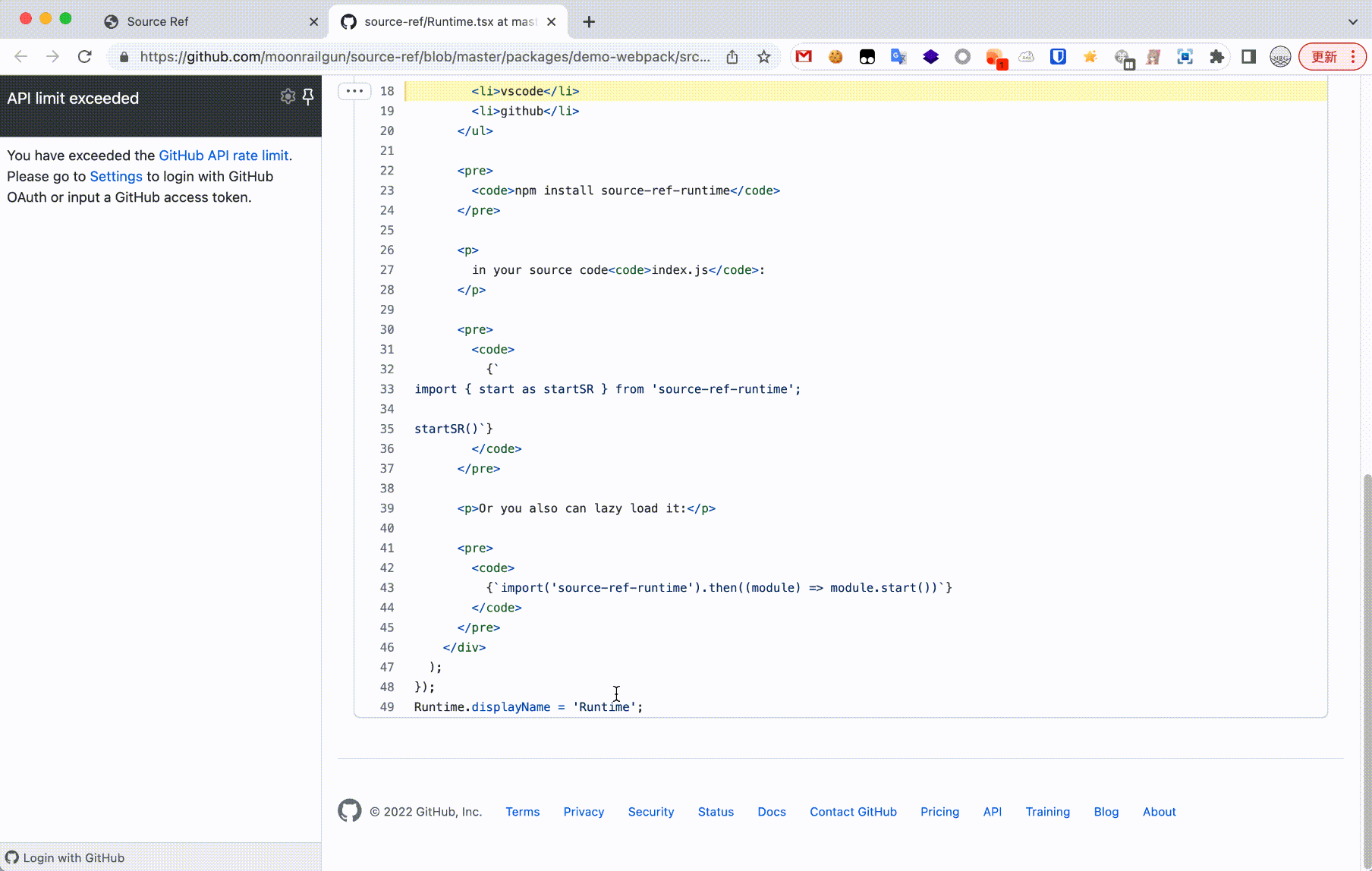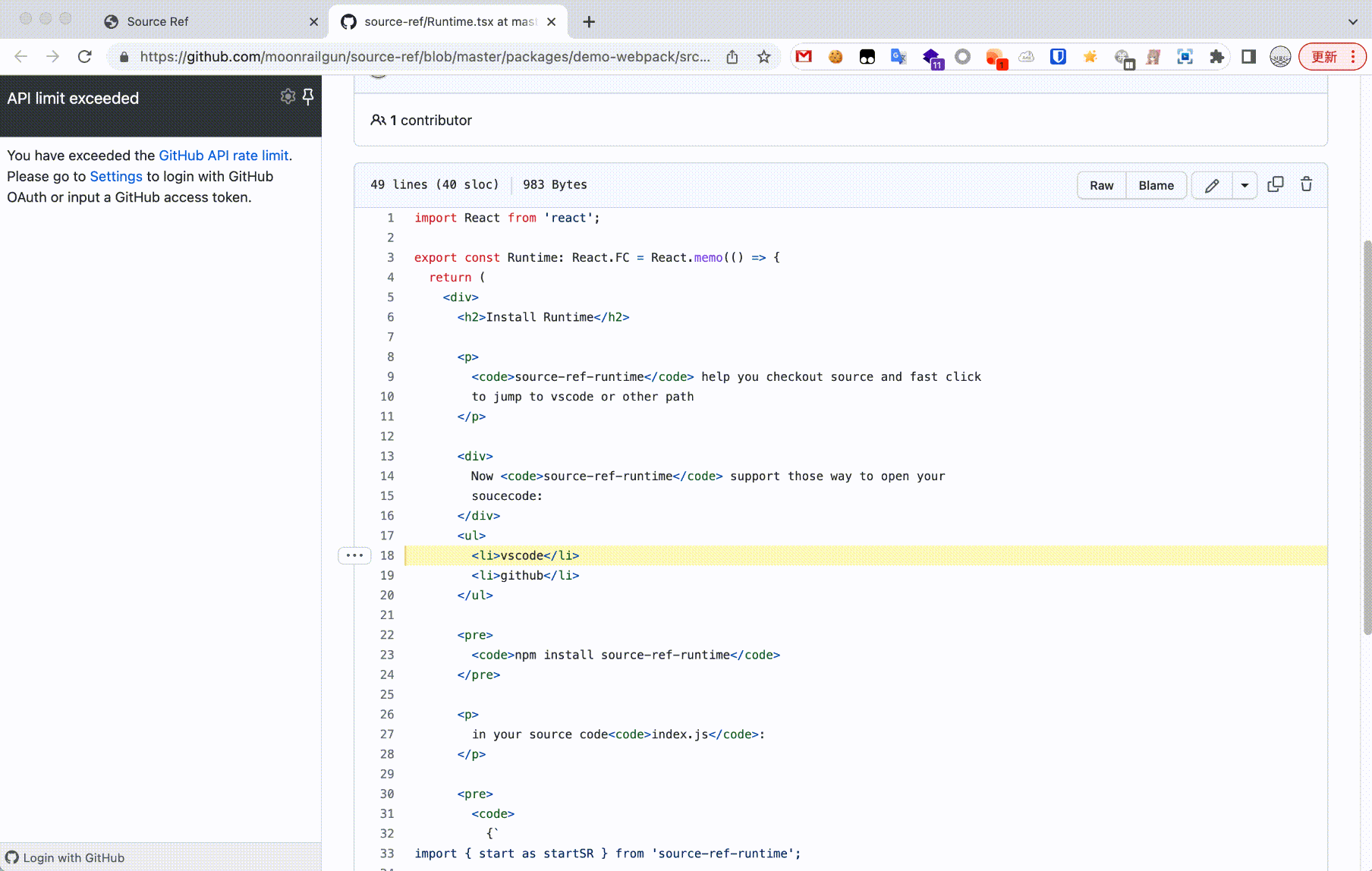
registerApp(appInfos) { const appList = Object.values(appInfos); // @ts-ignore router.registerRouter(appList.filter((app) => !!app.activeWhen)); // After completion of the registration application, trigger application mount // Has been running after adding routing to trigger the redirection if (!Garfish.running) return; routerLog('registerApp initRedirect', appInfos); initRedirect(); }, }; }; }
{ name: 'router', registerApp(appInfos) { const appList = Object.values(appInfos); router.registerRouter(appList.filter((app) => !!app.activeWhen)); // After completion of the registration application, trigger application mount // Has been running after adding routing to trigger the redirection if (!Garfish.running) return; routerLog('registerApp initRedirect', appInfos); initRedirect(); }, }
exportconst normalAgent = () => { // By identifying whether have finished listening, if finished listening, listening to the routing changes do not need to hijack the original event // Support nested scene const addRouterListener = function () { window.addEventListener(__GARFISH_BEFORE_ROUTER_EVENT__, function (env) { RouterConfig.routerChange && RouterConfig.routerChange(location.pathname); linkTo((env asany).detail); }); };
if (!window[__GARFISH_ROUTER_FLAG__]) { // Listen for pushState and replaceState, call linkTo, processing, listen back // Rewrite the history API method, triggering events in the call
let appInfo = generateAppOptions(appName, this, options);
const asyncLoadProcess = async () => { // Return not undefined type data directly to end loading const stop = awaitthis.hooks.lifecycle.beforeLoad.emit(appInfo);
if (stop === false) { warn(`Load ${appName} application is terminated by beforeLoad.`); returnnull; }
//merge configs again after beforeLoad for the reason of app may be re-registered during beforeLoad resulting in an incorrect information appInfo = generateAppOptions(appName, this, options);
assert( appInfo.entry, `Can't load unexpected child app "${appName}", ` + 'Please provide the entry parameters or registered in advance of the app.', );
exportclassApp{ asyncmount() { if (!this.canMount()) returnfalse; this.hooks.lifecycle.beforeMount.emit(this.appInfo, this, false);
this.active = true; this.mounting = true; try { this.context.activeApps.push(this); // add container and compile js with cjs const { asyncScripts } = awaitthis.compileAndRenderContainer(); if (!this.stopMountAndClearEffect()) returnfalse;
// Good provider is set at compile time const provider = awaitthis.getProvider(); // Existing asynchronous functions need to decide whether the application has been unloaded if (!this.stopMountAndClearEffect()) returnfalse;
// Performs js resources provided by the module, finally get the content of the export asynccompileAndRenderContainer() { // Render the application node // If you don't want to use the CJS export, at the entrance is not can not pass the module, the require awaitthis.renderTemplate();
// Execute asynchronous script return { asyncScripts: newPromise<void>((resolve) => { // Asynchronous script does not block the rendering process setTimeout(() => { if (this.stopMountAndClearEffect()) { for (const jsManager ofthis.resources.js) { if (jsManager.async) { try { this.execScript( jsManager.scriptCode, {}, jsManager.url || this.appInfo.entry, { async: false, noEntry: true, }, ); } catch (e) { this.hooks.lifecycle.errorMountApp.emit(e, this.appInfo); } } } } resolve(); }); }), }; } }
exportfunctioncreateAppContainer(appInfo: interfaces.AppInfo) { const name = appInfo.name; // Create a temporary node, which is destroyed by the module itself let htmlNode: HTMLDivElement | HTMLHtmlElement = document.createElement('div'); const appContainer = document.createElement('div');
privateasyncaddContainer() { // Initialize the mount point, support domGetter as promise, is advantageous for the compatibility const wrapperNode = await getRenderNode(this.appInfo.domGetter); if (typeof wrapperNode.appendChild === 'function') { wrapperNode.appendChild(this.appContainer); } }
======================================================================= = OpenFaaS has been installed. = =======================================================================
# Get the faas-cli curl -SLsf https://cli.openfaas.com | sudo sh
# Forward the gateway to your machine kubectl rollout status -n openfaas deploy/gateway kubectl port-forward -n openfaas svc/gateway 8080:8080 &
# If basic auth is enabled, you can now log into your gateway: PASSWORD=$(kubectl get secret -n openfaas basic-auth -o jsonpath="{.data.basic-auth-password}" | base64 --decode; echo) echo -n $PASSWORD | faas-cli login --username admin --password-stdin
faas-cli store deploy figlet faas-cli list
# For Raspberry Pi faas-cli store list \ --platform armhf
faas-cli store deploy figlet \ --platform armhf
# Find out more at: # https://github.com/openfaas/faas
/* * ATTENTION: The "eval" devtool has been used (maybe by default in mode: "development"). * This devtool is neither made for production nor for readable output files. * It uses "eval()" calls to create a separate source file in the browser devtools. * If you are trying to read the output file, select a different devtool (https://webpack.js.org/configuration/devtool/) * or disable the default devtool with "devtool: false". * If you are looking for production-ready output files, see mode: "production" (https://webpack.js.org/configuration/mode/). */ /******/ (() => { // webpackBootstrap /******/var __webpack_modules__ = ({
/* * ATTENTION: The "eval" devtool has been used (maybe by default in mode: "development"). * This devtool is neither made for production nor for readable output files. * It uses "eval()" calls to create a separate source file in the browser devtools. * If you are trying to read the output file, select a different devtool (https://webpack.js.org/configuration/devtool/) * or disable the default devtool with "devtool: false". * If you are looking for production-ready output files, see mode: "production" (https://webpack.js.org/configuration/mode/). */ /******/ (() => { // webpackBootstrap /******/"use strict"; /******/var __webpack_modules__ = ({
// The module cache var __webpack_module_cache__ = {};
// The require function function__webpack_require__(moduleId) { // Check if module is in cache var cachedModule = __webpack_module_cache__[moduleId]; if (cachedModule !== undefined) { return cachedModule.exports; } // Create a new module (and put it into the cache) varmodule = __webpack_module_cache__[moduleId] = { // no module.id needed // no module.loaded needed exports: {} };
// Execute the module function __webpack_modules__[moduleId](module, module.exports, __webpack_require__);
// Return the exports of the module returnmodule.exports; }