TRPG Engine 是我一直坚持维护的一个开源项目。正如所有的开源项目都起源于开发者的兴趣,TRPG Engine也是我对于跑团这一小众领域的兴趣。
我在没有支援没有赞助,单凭个人爱好独立坚持开发3年以上不间断。前端代码累计提交2700+, 后端代码累计提交1200+,风雨无阻。
谨以此文,分享一下我维护这个开源项目的经历。并与千千万万独立坚持的开源人共勉。
起初
所有的个人项目都起源于想做。因为我想做,因此我建立了这样的项目。最初的目的很单纯,就是作为我学习React的一个实践。
最初选用的技术栈是React + Redux。之所以用React是为了可以共享一部分的代码到React Native, 这样的搭配会很大的减少重复逻辑的开发与后期的维护,以减少成本。
而事实是我在两者共存与中间代码上花费了很多的精力,写了很多中间脚本使网页版与RN版能够相互协作。
明确定位
一个项目,如果要走的长远,必须明确你的产品定位与目标用户。比如同样作为即时通讯应用, 钉钉瞄准的用户群是上班族,slack的用户群是开发者,discord的目标用户是游戏玩家,而qq的用户群是小学生。以此为原点,钉钉开发出了一系列日历,考勤,协同,已读未读,ding等功能。slack只做了大量机器人,discord专注于语音会话与大用户群组聊天,而qq则整出了很多花样。
明确自己的定位,其目标一定是解决某种痛点与缺陷,做出任何的抉择都需要考虑是不是符合自己的定位。一个明确的定位可以帮助你不会花费无意义的时间在没有收益的功能上。
时刻保持热情与思考
时刻记住,项目是为自己做的。它不是一种谋生工具,而是一种兴趣爱好。它最初应当起源于你对现状的小小不满,终止于对此兴趣的终止。不妨增加一些筹码:比如它可以作为你的游戏场,比如他可以作为你谋求更高事业渠道的凭证,比如他可以是你与你伴侣之间的小小私人空间,比如你可以这样告诉自己,你的每一行代码都有可能帮助到素未蒙面的陌生人,而他会感谢你的无私付出。这些会帮助你时刻保持热情与动力,而不至于让这个项目半途而废。
维护自己的门面
如果一个项目想要宣传,一个门面则非常重要。这可能是一个README, 一片文章,一个官网。但是如果没有任何说明,告诉别人这是什么,你在做什么。又能期待谁来阅读你的源码呢?
自己是第一用户
对于个人项目来说,自己才是自己产品最忠实的用户,只有这样才能不断发掘产品的不足,并不断改善。如果自己都不想用自己的产品,那么这个产品还有存在的必要么?
开发
回到技术细节:
因为技术在不断更新。而有的库又逐步步入生命周期的终结,很多情况不得不花费时间去迁移。
而TRPG Engine经历过几次大的迁移/迭代:
- 原来
TRPG Engine的后端是使用的node-orm2. 然后这个库被弃用了。因此花了很大经历将其迁移到sequelize,包括代码的修改与数据库的变更。这个没什么好分享的,纯粹是当时的选择有限,而库的生命周期比较短。 - 最早的
TRPG Engine使用的是用纯粹的js写的,但是随着业务的不断增多,代码复杂度的变高,我选择使用Typescript对我的项目进行重构。从长远来看这一步是非常值得的,TS的类型系统长远的帮助到了一个项目的健康发展。(其实有点小遗憾,从目前的角度来看flow在一些细节做得比ts更加好)。 - 从
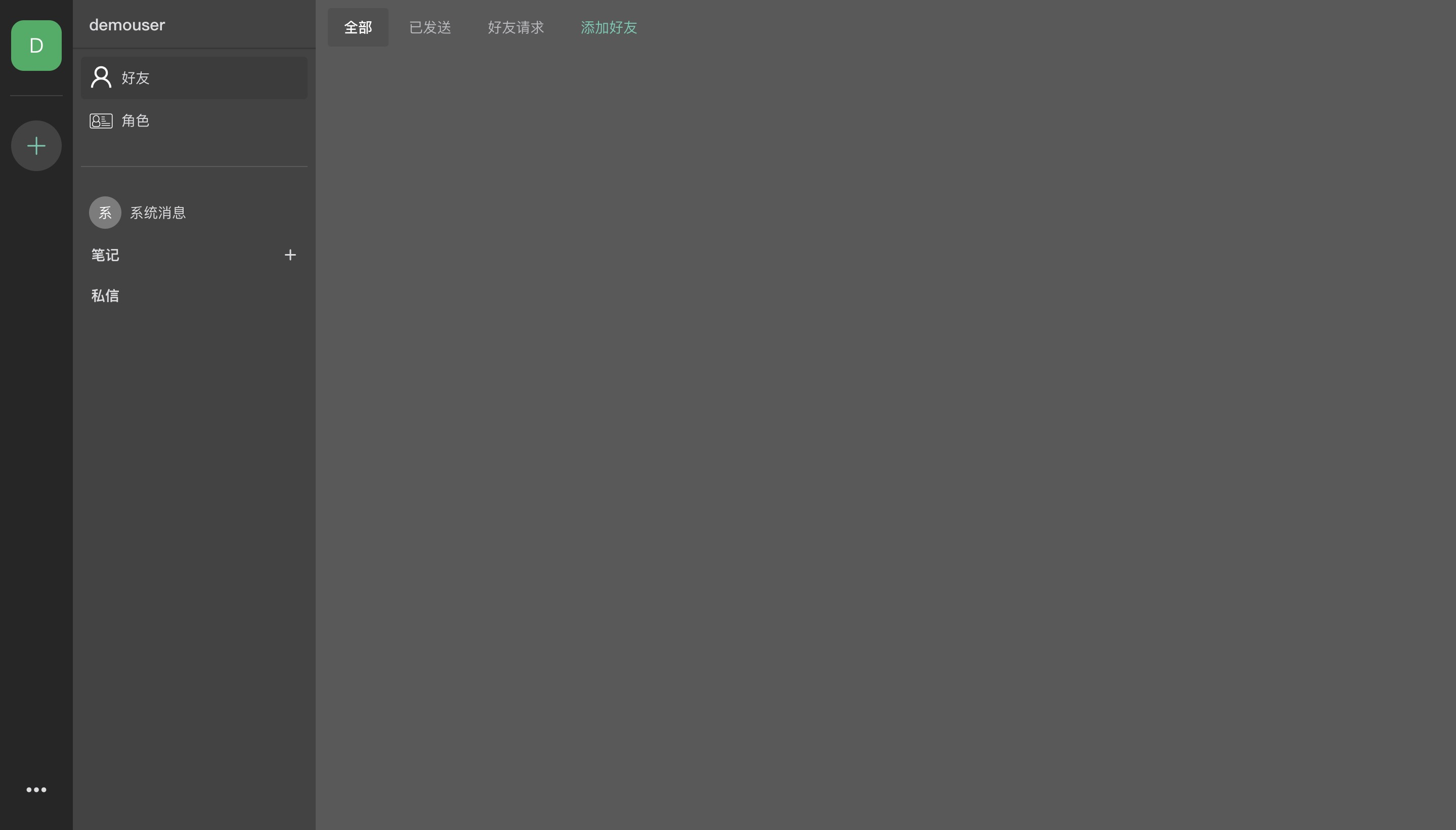
React ClassComponent到React Hooks: hooks无疑拥有更高的抽象性,使用Hooks能抛弃HOC这种很难被typescript支持的写法。同时更方便代码的复用,特别是对于React和React Native代码并存的项目来说。 - 前端重构, 重写界面。原来的TRPG Engine是参考的钉钉设计的,但实际的迭代中,频道的需求更为突出。即需要由原来的单层消息列表变成双层消息列表。因此花费了几个月时间写了一版类似于
Discord设计的新版页面,并且颜色也从原来的亮色变成保护眼睛的暗色。
善用单元测试
为了一个项目的长远发展,测试用例与持续集成都是必要的。特别是单元测试,在很多时候能帮助到项目的提前预知问题。坚持每个bug都有一个对应的单元测试用例,防止再次出现类似的问题。
TRPG Engine 虽然开始写测试用例比较晚,但是一旦有机会就会补充一些测试用例,以防止出现一些边缘问题。
目前TRPG Engine前端有223个测试用例,后端有284个测试用例,还远远不够一个项目的健康发展。
学会数据迁移
为了方便数据库的升级,自己fork了一个sequelize-auto-migrations库用于生成数据库的迁移脚本, 因为原作者已经不维护了。
数据库迁移脚本可以保证在任意环境下都能生成正确的数据库格式。这对于关系型数据库来说非常重要。
兴趣是原始驱动力
与商业项目不同的是,个人项目可以把一切自己感兴趣、想做的东西都想办法以某种形式糅合到自己的项目中。
TRPG Engine就拥有这些有意思的系统:
- 基于xml描述与js沙盒的动态计算的表单系统
- 基于slate实现的笔记系统与富文本输入框
- 基于meta信息的动态面板
- 基于BBCode的消息解释器
运维
为了维护与运营这个项目,唯一的支出就是在服务器和OSS上了,零零散散也花费了几千元在上面了。一台2核4G的主服务器, 在主服务器上运行Mysql, Redis与Mysql。另外还有一台1核1G的小型服务器作为语音服务器与测试服务器。前端的代码都是本地编译好后提交到第三方对象存储上,这样用户的访问会更加迅速与快捷。
赞助?
曾经也考虑过要不要和别人一样放出二维码,看看能不能获得一些打赏,后来想了想还是算了。一方面没有多少的关注,我本人也比较低调不善于宣传。另一方面感觉,掺杂了利益后的开源项目,总感觉失去了纯粹性。爱好只能是爱好,如果成为一种牟利方式,那么可能就不像当初那么纯粹了。
感谢
最后感谢所有开源作者的无私奉献,正是你们存在才能让这个互联网世界变得更加精彩。